


HTTPS协议因其具有安全属性,完全有将HTTP取而代之的趋势。然而这个进程并没有很顺利,因为HTTPS实施起来有几个难点,其中有一个是它的性能问题。本文分享了京东金融私有云在HTTPS性能优化上的实践,希望对有意切换HTTP到HTTPS的你有所帮助。
造成这种问题的原因是我们平常最为广泛使用的超文本传输协议(HTTP,HyperTextTransferProtolcol)在设计之初并没有考虑安全性问题,导致如今大量数据在网络上明文传输。
HTTPS是什么
HTTPS(HTTPoverTLS)是超文本传输安全协议(HyperTextTransferProtocolSecure),是一种通过计算机网络进行安全通信的传输协议,最初由网景公司(Netscape)于1994年提出。
HTTPS在不安全的网络上创建一条安全信道,通过数据加密、数据完整性校验、身份认证等手段,对窃听和中间人攻击进行合理的防护。
数据加密,就像我们邮寄包裹,任何的中间人都无法知道里面装了什么
完整性校验,假设中间人对包裹做了手脚,我们能轻易的识别并且拒绝签收
身份认证,确保包裹一定是包裹单上的收件人签收的。
HTTPS是大势所趋
如今,全世界都对HTTPS抛出了橄榄枝:
微信小程序要求所有的请求必须是HTTPS请求
苹果要求所有IOSApp2016年底强制使用HTTPS加密,虽然该计划暂时被延期
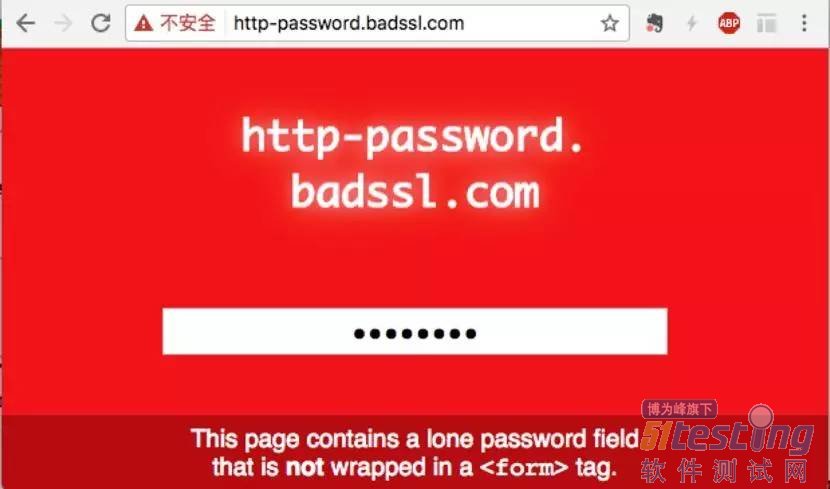
Chrome浏览器对HTTP页面提出警告,如下图,当前为中性警告,即默认情况下只有当HTTP页面检测到密码或信用卡字段时才会提示不安全,但同时Chrome也明确表示,该计划将会越来越严格,最终会对所有HTTP页面提示不安全。
HTTPS存在的问题
HTTPS是大势所趋,但是HTTPS的覆盖率并不广,只有像BATJ等大型互联网企业才在最近几年完成了全站HTTPS的迁移,究其原因主要是HTTPS的实施成本过高:
延时增加,普遍增加二到四个RTT,最严重情况下可能会增加七个RTT
吞吐率下降,服务端消耗CPU严重,完全握手下,整体性能会下降到HTTP的10%甚至更低
用户访问延时的增加,给公司产品、服务质量造成不利的影响。从另外一个层面来讲,由于服务端性能骤降,可能需要原本接入集群基础上数倍的机器数量才能支撑当前用户访问。
而且证书的选择、后期运维如私钥存储都具有一定的技术门槛,比如如何在安全性和兼容性层面达到相对平衡,这使得许多公司望而生畏。
本文不涉及HTTPS的实现原理以及最佳运维实践,主要谈谈京东金融私有云在HTTPS性能提升上的一些经验。
优化经验
京东金融私有云HTTPS卸载服务基于Nginx和Openssl深度定制,性能优化主要从延时和吞吐率两个维度考虑。
TLS Record Size动态调整
TLSRecord协议工作在表示层,在传输层和应用层之间提供诸如数据封包,加解密,HMAC校验等功能,如下图:

Nginx在建立TLS连接时会为每个连接分配Buffer用于发送原数据(TLSRecordSize,默认16KB),当服务端发送数据时,数据会被切分成16KB的多个块,每个块用MAC签名,加上协议的元数据以及被加密后的原数据形成一个TLSRecord结构发送到客户端,在客户端只有当协议栈接收到完整的TLSRecord时才能够解密验证,才会向应用层提交。
由于16KB的包大小以及丢包等因素的影响,相对于TCP,HTTPS的TTFB(TimeToFirstByte)延时较大。
TTFB是判断网站性能的重要指标,主流浏览器都是边下载边解析渲染的,延时较大最直观的影响就是最终用户在浏览器端看到内容的速度较慢。
当然TLSRecordSize也不能一味地变小,比如当它等于MSS时,变小就会有较大的头部负担,导致整体吞吐量下降。
我们当前使用的是TLSRecordSize动态调整算法,随着CWND从Initcwnd增长到16K,在延时和吞吐量之间达到相对平衡。
False Start
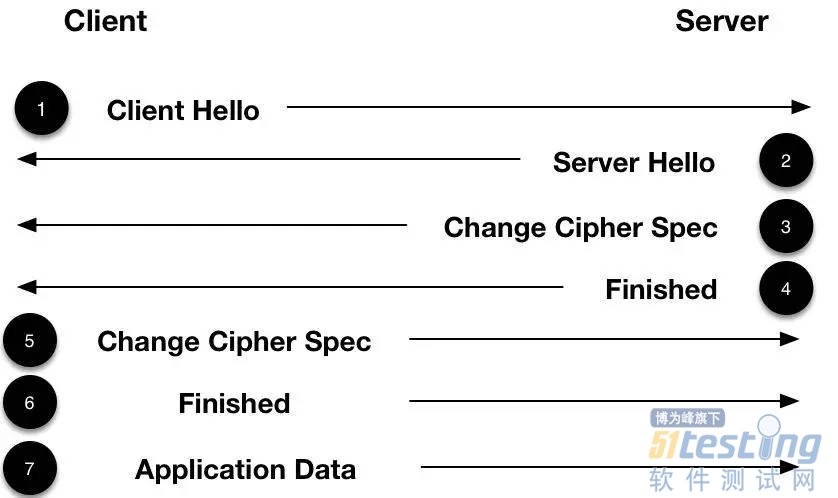
通过启用FalseStart,客户端可以在ChangeCipherSpec和Finished报文后立即发送应用数据,使得原本需要两次RTT的完全握手变更为一次RTT。
国内南北网络的平均延时是50ms,这也就意味着每一个地处南方的用户访问地处北方的站点,人均可节省50ms,效果显著。
根据RFC7918文档,只有使用具有前向安全的秘钥交换算法以及足够强度的对称加解密算法时FalseStart才会启动。
需要注意的是,Chrome浏览器为了解决一些特殊SSL服务如SSLTerminator硬件设备的不兼容性,要求只有和支持NPN/ALPN的服务端通信才会开启FalseStart。
NPN随着SPDY被HTTP/2代替已被Chrome移除,而ALPN只在Openssl-1.0.2后才开始支持,加之Openssl新版本的Bug修复以及性能优化,所以如果有条件建议在服务端部署较新版本的Openssl。
OCSPS tapling
OCSP设计之初是CRL(CertificateRevocationList)的替代品,希望通过在线实时的网络交互检查证书吊销状态,但是这个功能有点鸡肋:
暴露用户隐私,Https旨在提高安全性和保护隐私,OCSP显得有点背道而驰
OCSPResponder基本在国外,而且服务能力未知,假设访问OCSPResponder的延时很大,或者是客户端和OCSPResponder的链路主动或被动地断开,客户端无法很好地确定是否应该接受证书。
OCSPStapling通过服务端对OCSP结果的预取并把结果随着证书一起发给客户端,从而绕过客户端的在线验证过程,可以很好地解决上边两个问题。
我们在自己的网站中都应该配置使用OCSPStapling,但是需要注意的是OCSPStapling也并非完全能起到检查证书吊销的作用,以至于像Chrome浏览器就已经完全不做证书吊销检查了。
HSTS
HSTS(HTTPStrictTransportSecurity)通过在HTTPSResponseHeader中携带Strict-Transport-Security来告知浏览器:以后请直接通过HTTPS访问我,当第二次用户在浏览器端访问HTTP站点,浏览器会在内部做307重定向,直接通过HTTPS访问。如下图:
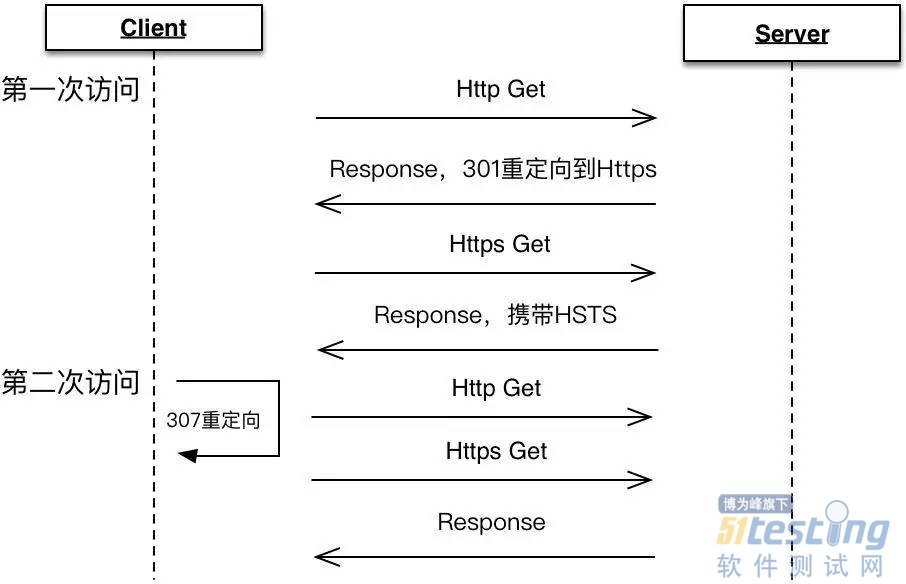
通过HSTS能有效地避免SSL剥离攻击,并能减少2个RTT,强烈建议配置使用。但同时也需关注首次访问的中间人攻击,以及准备回滚措施以防HTTPS回滚。
会话复用
常见的会话复用有SessionID和SessionTicket两种形式,其中SessionID是TLS协议的标准字段,而Ticket是扩展字段,根据相关统计,Ticket的客户端支持率只有40%左右。
通过会话复用,把完全握手变更为简单握手,避免最耗时的秘钥协商阶段,能显著提升性能,如下图,客户端在发起连接时携带上一次完全握手时服务端返回的SessionID,服务端收到后在内存中查找缓存的会话信息并恢复加密通信。
但是原生Nginx只实现了单机版本的会话复用(SSL_SESSION_CACHE关键字),而当前我们都习惯以集群方式部署Nginx来达到高可用,所以我们通过新增Nginx模块以及对Nginx源码的少量改造,支持分布式会话复用,如下图,无论请求落到哪一台Nginx机器,都可以复用已缓存的会话信息。

该Nginx模块
(ngx_ssl_session_cache_module)
已经开源,支持Redis和Memcached两种分布式缓存系统,且对Openssl没有任何代码依赖,欢迎使用,详见https://github.com/hzarch/ngx_ssl_session_cache_module.git.
双证书
256位ECC秘钥加密强度等同于3072位RSA秘钥水平且性能更高,而且秘钥更短意味着更少的存储空间,更低的带宽占用,所以对于有条件的企业建议开启ECC&RSA双证书支持。
对比ECDHE_RSA、ECDHE_ECDSA秘钥交换认证算法所需的RSA_SIGN、ECDSA_SIGN算法,以下是我们在普通工作站上通过OPENSSLSPEED测试的性能数据,可以明显看到ECDSA_SIGN性能提升。

对称加密优化
AES-GCM是目前常用的分组加密算法,缺点是性能低以及移动端耗电量大,所以谷歌在2014年推出了一种新的流式加密算法CHACHA20-POLY1350,在ARM平台上性能是AES-GCM的3-4倍。
Intel从Westmere处理器开始支持一种新的x86指令扩展集AES-NI,AES-NI能从硬件上加速AES的性能,在支持AES-NI指令集的主机上实测AES-GCM性能是CHACHA20的5倍左右。
原先我们为权衡兼容性和安全性,所以参考Mozilla的推荐.
默认采用中档配置,该配置假设客户端不支持AES-NI,所以CHACHA20优先于AES-GCM,然而随着底层技术的发展,移动端从ARMV8-A架构开始逐渐支持AES指令集。
像常用的IPhone5S,GalaxyNote4(Exynos),红米2,锤子T2,荣耀5X等都是基于的ARMV8架构,考虑到当前互联网企业的用户都以年轻群体为主,所以我们改变策略优先使用AES-GCM。
HTTP/2
HTTP/2是HTTP/1.1在1999年发布后的首次更新,HTTP/2带来了诸如多路复用、头部压缩、二进制分帧等特性,能大幅提升Web性能。
使用时可以让客户端选择或通过NPN/ALPN动态协商是采用HTTP/1.XoverTLS还是HTTP/2overTLS,而且后端服务无需修改代码进行适配,具有比较大的灵活性。
但是也需要注意HTTP/2并不是万能的解药,使用时需对网站本身的情况做充分评估,需规避诸如为HTTP/1.X调优而提出的域名散列等问题。
加速卡
以上所有的优化都是软加速范畴,主要目的是减少RTT,但是对于无法避免的完全握手,服务端还是会进行大量的加解密运算,以ECDHE_RSA为例,像RSA_Sign函数在IntelE5-2650V2主机上每秒只能执行1.2W次左右,而此时24个核已全是满载状态。
CPU向来都不适合处理大规模的浮点运算,解决这类问题性价比最高的方式无疑是采用硬件加速卡(GPU就是其中一种),通过把加解密运算转移到加速卡来替换Openssl的加解密处理。
加速卡安装在主机的PCIE插槽内,受限于主机PCIE插槽数量,支持线性扩容,根据加速卡类型不同,像RSA_Sign计算性能在单卡状态下都能提升3-6倍左右。
算法分离
利用软优化以及硬件加速卡,基本能满足大部分的业务场景,但这却不是最优解,我们发现:
●不同厂家不同型号的加速卡存在性能差异,同型号的加速卡不同算法也存在性能差异,像我们测试的一款Cavium卡,ECDHP256和RSA2048_Sign存在20%的性能差距
●Openssl-1.0.2版本实现了更快速以及更安全的EC_GFp_nistz256_method方法用于P256曲线操作,该方法利用了IntelAVX扩展,性能提升显著。
在老旧的IntelE5-2620主机测试Openssl-1.0.2单核ECDH性能达到8040,4倍于Openssl-1.0.1u,24核全开时性能达到9.7W,在E5-2650V2上,极限性能更是达到17.5W,远高于加速卡单卡的5-8W。
正是由于这种差异性,我们提出算法分离的架构,希望充分利用硬件性能。

如上图,通过这种架构我们把接入集群从CPU密集型转换成IO密集型,具体的算法运算,私钥存储等都在专有集群完成,极大地增强了接入集群的可扩展性。
另外通过这种架构我们不仅可以充分利用闲置的计算资源,也可以最优化HTTPS卸载服务的吞吐率,而且对于计算集群的增删改,我们支持在Web管控端上批量修改,卸载服务会实时拉取并应用修改,此外再辅以计算集群的整体监控,极大地简化了运维复杂度。
性能指标
以上优化总结起来就是面向延时和吞吐率的优化,以下是我们在测试环境测试的一组单机性能数据(IntelE5-2650V2),仅供参考。
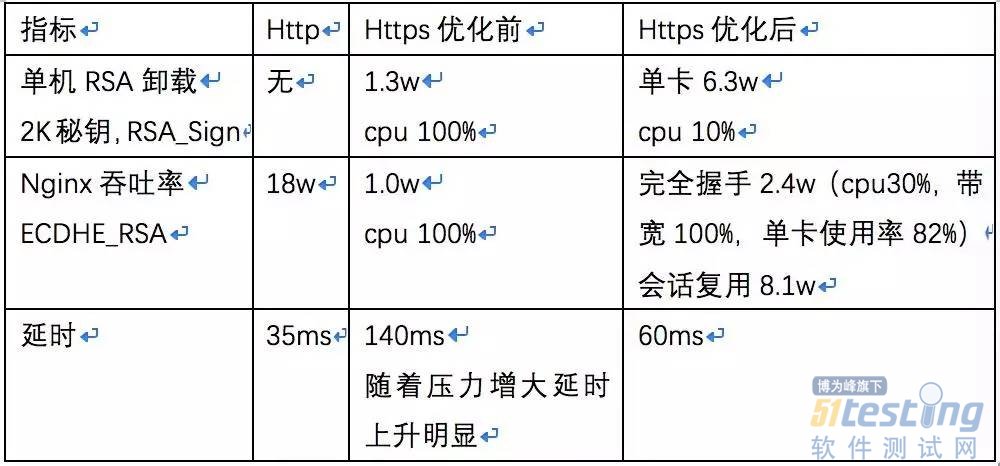
由于无法优化浏览器端代码,当前延时只能优化到一个RTT,若客户端私有,可参考TLSV1.3开发0-RTT协议。
总结
HTTPS是个系统性工程,而性能优化只是其中一块,还需要解决诸如证书、运维、网络等问题,但是好消息是,随着国内一些大企业实施HTTPS已经有一些最佳实践被探索,以及诸如Let'sEncrypt等免费DV证书推出,HTTPS的成本正在逐渐降低,所以在此呼吁各企业尽快上线HTTPS,保障网站的信息数据安全。











