本文附简易案例数值分析
A/B测试不是简单的将用户分成两组,设计转化率指标,实验结束后直接对比转化率就可以了!

本文源于A/B测试 by Google (免费课程)学习总结,本文仅是对课程第一节内容的学习总结,感兴趣的朋友可以点击连接观看并深入学习,也希望大家可以一同学习并深入交流在实际工作中的A/B测试情况。
一、A/B 测试概述
1.1A/B test概念:A/B测试是一种用于在线测试的常规方法,可用于测试新产品或新功能,需要设置两组用户,将其中一组设置为对照组,采用已有产品或功能,另一组采用新版产品或功能,通过对比分析上述用户做出的不同响应数据,确定哪个版本更好。
1.2A/B test 适用场景:通过大范围的用户数据观察,如新功能界面中增加了内容,不同的外观,不同的按钮配色,都可以使用A/B测试,帮助产品持续优化。案例:google曾在用户界面中运行了42不同蓝色阴影,观察用户有什么反响。amazon做过测试,每个页面增加100毫秒延迟,收入会降低1%,google也得出类似结果。
1.3A/B test 局限性:A/B测试不适合做全新体验的效果评估,因为全新的体验存在两个问题,比较基准是什么?数据对比需要多长时间才能看到效果?(面对低频服务-如租房,很难通过A/B测试看出推荐对于人们的行为影响)。
1.4A/B test 练习题(评论区写下你的选项,回复给你正确答案):
在以下什么情况下你可以考虑A/B测试?
A:你想要知道你的电商网站是否完整,是否存在用户想要购买但是平台无法提供的商品
B:公司已经有了免费服务,但想要提供有其他功能的高级服务,需要客户升级或付费
C:假设一个网站提供电影推荐服务,通过新的算法对可能的建议进行排序
D:假设你想要改变基础架构的后台,会影响到页面加载速度和用户看到的显示结果
E:一个汽车销售网站,考虑做出改变,想知道改变是否更可能再次访问网站或者向他们的朋友推荐
F:假设一家公司想要更新他们的品牌形象,如主页的logo,改版后对用户行为产生哪些影响
G:假设你想改版移动应用首页,想要调整信息架构,观察对用户行为产生哪些影响
当A/B测试不适用时,可以通过用户操作日志检查或观察来分析,也可以通过随机的试验,进行前瞻性分析。也可以使用焦点小组,面对面沟通,问卷调查,用户评价分析等方法获得定性数据,补充A/B测试的定量测试结果。
实操案例设计:wap首页改版,wap首页作为导流落地页,主要功能为引导用户完成注册。

二、A/B 测试度量选择
A/B测试前一定要设计合理的测试度量指标,通过审核核心指标判断不同测试版本的效果如何,如果需要测试首页改变对于用户注册带来的效果,可以使用独立访客点击率作为测试首页改变的度量值。
独立访客点击率=独立访客点击注册按钮数/独立访客登录首页数
实操案例设计:
独立访客注册按钮点击率=独立访客点击注册按钮数/独立访客登录着陆页数
独立访客注册完成率=独立访客注册完成数/独立方可登录着陆页数

三、二项分布和置信区间
样本数不同,则结果的置信度会收到影响,第一组实验,独立访客点击注册按钮数=100,独立访客登录首页数=1000,这注册改版后的独立访客点击率=100/1000=10%,那么在做一组实验,如果独立访客点击注册按钮数=150,是否异常?可以利用统计学知识进行测算测试结果是否可信。
数据中经常会有特定的一些分布,帮我们了解数据变化规律,如正态分布,T分布,卡方分布等。我们关于首页点击情况符合二项分布。
二项分布就是重复n次独立的伯努利试验。在每次试验中只有两种可能的结果,而且两种结果发生与否互相对立,并且相互独立,与其它各次试验结果无关,事件发生与否的概率在每一次独立试验中都保持不变,则这一系列试验总称为n重伯努利实验,当试验次数为1时,二项分布服从0-1分布。--【源自百度百科】
二项分布需要满足以下条件:两种结果;实验彼此独立,不相互干扰;事件要遵循同一种分布。
平均概率:p=x/n检验是否符合正态分布:n*p>5,n(1-p)>5置信区间宽:m(误差幅度)=z(置信度)*SE(标准差);SE=√ ̄(p(1-p)/n)μ±1.96标准误之间包含所有平均数的95%,μ±2.58标准误之间包含所有平均数的99%

四、统计显著性分析
假设检验或推断是统计学中的一个概念,以量化的方式,确定你的结果发生的概率。
首先我们需要一个零假设或者说基准,也就是对照组和实验组之间的概率没有区别,然后要考虑的是备择假设。要想确保结果具有统计显著性,那么需要计算结果是偶然出现的可能性。要计算这个概率,你需要先假设,如果实验没有效果结果会怎么样,这就是所谓的零假设,记为Ho,我们还需要假设如果实验有效,那结果会是怎样,这称为备择假设,记为HA。
| 合并标准误差(实验中观测差异是否具有统计显著性)Xcont,Xexp;Ncont,Nexp;Pexp=Xcont/Ncont;Pcont=Xcont/NcontPpool=(Xcont+Xexp)/(Ncont+Nexp)SEpool=√ ̄(Ppool*(1-Ppool)*(1/Ncont+1/Nexp))d=Pexp-Pcontm=z*SEpoolH0:d=0,d~N(0,SEpool)ifd-1.96*SEpool>0ord+1.96*SEpool<0,则可以拒绝零假设,认为差别具有统计显著性 |
从商业角度来说,2%的点击概率改变就具有实际显著性。
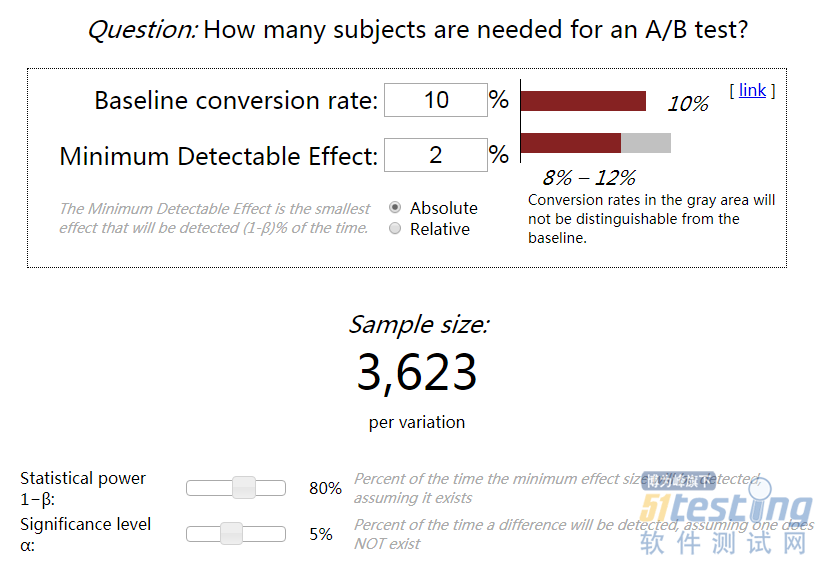
不同的实验观测样本数量,直接影响实验的有效性,那么如何设计科学的A/B测试呢?可以考虑使用下方工具,根据输入数值,自动计算合理的实验组和对照组的观察人数。
在线测算实验人数工具

工具说明
Significance level α:显著性水平是估计总体参数落在某一区间内,可能犯错误的概率,用α表示。显著性是对差异的程度而言的,程度不同说明引起变动的原因也有不同:一类是条件差异,一类是随机差异。它是在进行假设检验时事先确定一个可允许的作为判断界限的小概率标准。
Statistical power 1?β:统计功效(statistical power )是指, 在假设检验中, 拒绝原假设后, 接受正确的替换假设的概率。我们知道,在假设检验中有α错误和β错误。α错误是弃真错误, β错误是取伪错误。取伪错误是指, 原假设为假,样本观测值没有落在拒绝域中,从而接受原假设的概率,及在原假设为假的情况下接受原假设的概率。由此可知, 统计功效等于1-β。
首先要设计实验,鉴于可以控制对照组和实验组的网页浏览量,我们必须要确定,为获取统计显著性的结果,最能获取统计显著性的结果,这称为统计功效。功效与规模呈负相关,你想要探索的改变越小,或者是你想要的结果置信度越高你需要运行的实验规模就越大,这就是对照组和实验组需要更多的网页浏览量,大家可以尝试在计算器中修改数据,观察实验样本数量,如修改最低可观测效果,修改基准转化率,修改统计功效,修改显著性水平。
五、案例实操分享
5.1 实验设计背景
案例背景概述:wap首页改版,wap首页作为导流落地页,主要功能为引导用户完成注册。满足二项分布
计算最小实验样本:利用上图工具,我们将dmin定为2%,意思是新版本用户转化增加超过2%才有效,置信区间选择95%,经过计算最小实验样本数为3623人。