

为了让产品的质量可度量、可视化,我们可以建立一些指标数据,以帮助我们发现产品质量的各种问题,比如:被测功能模块发现Bug太晚,某位开发同学的代码质量一直很低,某个功能总是在兼容性方面存在大量问题等。有了问题之后,我们就可以有针对性地进行改进,有的放矢,从而使得被测产品的质量逐步改善。以搜狗的项目为例,我们建立的指标有以下三个方向:Bug、代码行和漏测问题数量。
关于Bug的指标
Bug是软件开发过程中最基本的问题载体,在这一方向,我们可以细化为几种数据指标,例如:
1.Bug数量分布(功能模块维度):
按照功能模块维度,分别统计Bug的数量(也可以是严重Bug数量)情况,该项指标用以反映哪个功能模块的质量情况最低。例如:搜狗输入法有语音输入、拼音输入、手写输入,分别统计某个版本这三个模块的Bug情况。

解释说明:
首先我们可以判断Bug数量高的模块是否合理。如上图所示,本次版本开发主要实现和修改的是语音功能,那么Bug数量多是合理的。
其次我们可以有针对性的部署测试策略。语音功能的问题数量较多,功能比较复杂,只是按照既有的测试计划可能模块质量覆盖不够全面,所以我们有针对性地对这个模块进行二轮、三轮甚至四轮的回归测试,或者安排更多地人力。
2.Bug数量分布(开发人员维度):
按照开发人员维度,分别统计每个开发人员所产生的Bug数量情况,该项指标用以辅助评估开发人员的代码质量情况。

解释说明:
这一指标可以帮助我们了解哪位开发的Bug修复压力最大(压力越大,连带Bug的可能性也会越大),测试人员可以留意对应开发的Bug修复率。
如果某位开发的Bug数量常年居高不下,测试人员就要注意小心了~~。
需要特别说明的一点是,Bug数量不能作为唯一评判开发人员代码质量好坏的数据,Bug数量是与开发人员提交代码量和模块复杂度成正比的,综合地查看Bug数量和代码提交量是比较可行的方法。
3.Bug易发现分布(功能模块维度):
Bug易发现是指一个功能模块在用户可触及的主路径上就会遇到的Bug,例如:在输入法的键盘上按下语音键进行语音输入时,功能不能使用。该指标用以统计提测模块的开发自测情况,数据越多说明提测时质量越差。
4.Bug易发现分布(开发人员维度):
同上,以开发人员维度进行分析统计。
5.Bug往返率(开发人员维度):
该指标用于统计Bug在缺陷管理系统中的来回指派数量的情况。比如:某Bug在开发人员A和测试人员B之间来回指派了3次,那么则统计开发人员A的Bug往返平均数量。
6.Bug发现的阶段:
该指标可选项有预测试、一轮测试、二轮测试、回归测试、上线前测试、上线后几个可选项,它用于体现Bug的发现时间段。
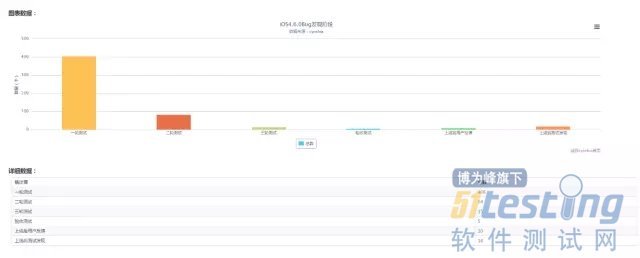
解释说明:
预测试一般是开发提测后进行1天的测试,用以评估提测的版本是否符合测试的要求。如果大量的Bug在预测试阶段发现(甚至是阻塞的Bug出现),说明提测版本的质量可能不好,这就需要督促开发给出质量更高的版本提测,以节省Bug沟通处理的成本,从而大大提升测试效率。
正式提测后,按照预期的效果,我们希望是大量的Bug在一轮测试阶段发现,少量的Bug在二轮测试阶段发现,极少量的Bug在回归测试阶段暴露。但是实际情况可能有所不同,如果二轮和回归阶段的Bug数量很多,这有可能是测试人员的测试方法、测试策略有问题,导致Bug暴露发现得比较晚;也可能是开发修复Bug时连带其他Bug数量多,这间接反映了开发修复Bug的方式方法可能有问题。
7.Bug产生的原因:
这一选项是Bug在提交测试验证时,由由开发人员填写的字段,该字段可选内容有:服务器问题、第三方SDK问题、适配性问题、UI显示问题、程序逻辑问题、性能问题、沟通不足问题、需求理解问题。(具体字段可选项可根据实际项目进行设定),这一指标用来辅助开发人员分析Bug产生的原因。
解释说明:
服务端问题(本例因为是客户端程序,所以选项中有服务端问题)如果存在大量的Bug,这说明服务端的质量控制不足。
第三方SDK问题。因为App一般会使用其他方提供的SDK直接调用,对于SDK的质量情况可以通过该项指标数据来暴露,如果问题集中且较多,后续应该推动SDK方提升其质量品质。
沟通不足、需求理解问题一般是工作配合类问题,如果是此类问题集中,应该重新评估整体项目流程运转是否正常有效。
关于代码的指标
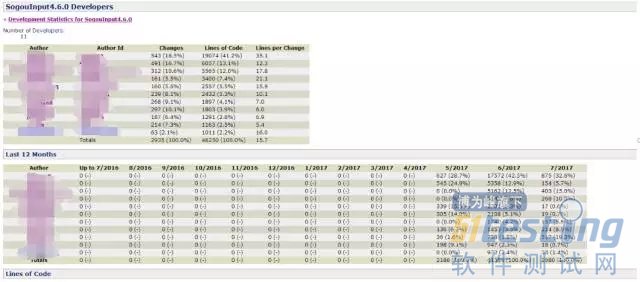
借助功能强大的StatSVN,我们可以方便地统计出与SVN相关的各种数据指标,如:每位提交者的情况、每月的代码提交情况,代码修改占代码总数的百分比、每天中哪几小时比较活跃、每周哪几天比较活跃、文件数量统计等,关于StatSVN的介绍网上有很多使用教程,本文不再赘述,请感兴趣的同学自行"搜狗 StatSVN"即可。
千行代码Bug率:
在搜狗输入法项目我们主要使用了StatSVN的一个数据项:开发人员代码行数量,再结合上述1中的Bug指标数据,我们可以得到一个新的指标数据:千行代码Bug率,该指标用于侧面体现开发人员的代码质量情况。
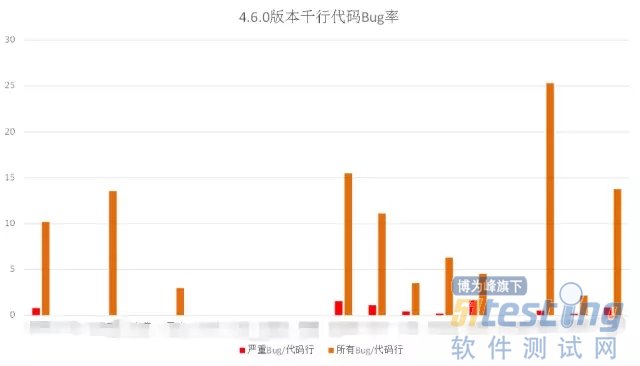
解释说明:
这一指标数据会定期发送给开发Leader,以便开发Leader对其下的开发人员质量情况有一个清晰的认识,同时也会督促开发人员提升代码质量意识。
关于漏测问题的指标
除了测试环节Bug及代码的统计分析,对于上线后用户反馈暴露的质量问题,也应加以统计分析。在搜狗测试部,我们通过Bug总结流程来进行这一环节的数据录入和统计。
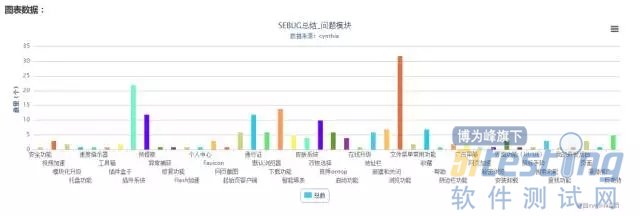
1.漏测问题数量分布(模块维度)
该指标从功能模块的维度,对线上用户反馈的问题进行统计分析,例如:搜狗浏览器的线上用户反馈数量最多的问题是浏览网页这一功能。
2.漏测问题原因类型:
根据以往的工作经验,我们将线上用户反馈的问题归为以下六大类,每一大类下细分小分类。
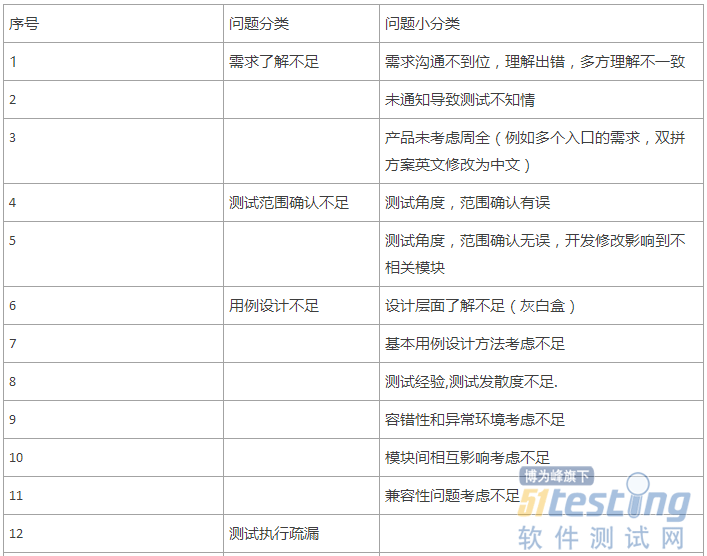
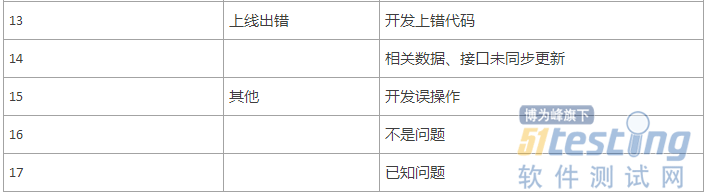

解释说明:
通过分析线上漏测的问题原因,可以发现测试、开发或者流程上的不足,以PC浏览器的分析为例:
浏览页面功能是TOP1被用户反馈的功能模块(这也符合浏览器最主要的功能就是浏览网页),进而发现这一功能出现问题最多的是兼容性站点的问题,或者是用户的测试环境比较复杂特殊导致的。
(882590) : 【问题类】打开某链接会稳定崩溃 (Google Doc)
(832095) : 【问题类】玩4399的小游戏时狙击枪不能开镜
(967951) : 【问题类】交通银行信用卡页面首次打开时输入框和验证码输入界面显示不全
基于以上的数据分析,我们重新制定了详细的浏览器站点兼容性测试方案,每个版本加大兼容性站点的测试,在测试阶段即发现了大量的Bug。
总结
作为项目管理者,我们可以通过分析项目每个版本的Bug数据、代码行数据、漏测的问题数量,发现数据背后的问题(开发问题、测试问题、流程问题等),针对问题寻找解决方案并实施,从而提升整个产品的质量控制。












