

前言:大数据的分布式调度是在进行数据ETL过程中起到了总体的承上启下的角色,整个数据的生产、交付、消费都会贯穿其中,本文从调度、分布式调度的特征展开,再对大数据调度个性化特征的一些阐述,由满足大数据使用的架构和业务场景的需求上娓娓道来,从实践的角度分享如何打造一个高可用、高效率、灵活性的大数据调度平台。

一、调度
从上个世纪50年代起,调度问题的研究就受到数学、运筹学、工程技术学等领域科学的重视[1],人们主要从数学的角度来研究调度问题,调度问题也同样被定义为”分配一组资源来执行一组任务”,以获得生产任务执行时间或成本的最优[2]。调度在计算机任务的实现可以依赖操作系统的定时任务进行触发(例如Linux系统的Crontab),主要针对单任务机制的触发,调度最基本的需要能够按时或者按照事件进行触发(At-least-once),如果任务不符合预期,还需要在应用端进行重试,最大可能保证任务被按时执行,并且成功执行,同时不能多次执行(Exactly once);但是在业务场景能保证可重复执行、一致性操作情况下对于争取能正常调度执行多次执行也是不可或缺的,比如给商户进行1min前的例行结算,如果结算是按照30min的时间窗口查找未结算的商户,那么就会容忍30min延迟,并且多次被执行也不会给商户多结算,因为在结算付款和重置是否结算标志位可以设计成原子性操作。所以在调度上能够做到按时、正确的执行,在业务方设计为了保证最终一致性也有一些架构上的取舍。
如果应用场景有上下游的协作,或者在任务执行会存在不同的宿主机来完成,或者为了保证任务高可用场景,就需要引入分布式调度的架构。
二、分布式调度
分布式调度是在单机的基础上发展起来,在综合考虑高可用、高效率、分布式协作的背景下逐步演进的调度方式,从单点调度到分布式协作是一个质变的过程,这个过程涉及到许多在单机并不存在的特征,下面针对重点展开聊下:
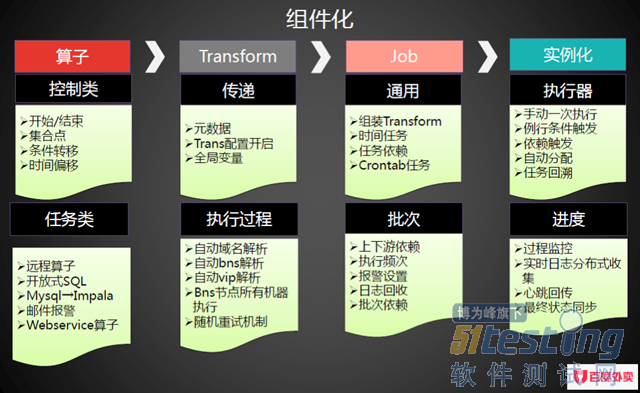
图1 分布式调度组件化分解图
2.1 调度器去中心化&高可用
涉及到分布式调度的协作,就需要有调度中心节点,同时要保证高可用的目的就需要调度中心节点是多节点发布,主备的方式去单点依赖。
2.2 宿主选择
分布式调度在任务执行阶段,可以在目标宿主中进行全部执行、N选M(N>=M>=1)的选择,宿主机具备相同类型任务互备的机制,在MPP(Massively Parallel Processor)架构中尤为常见,把大任务分而治之快速完成。也存在场景(比如外卖给商户结算)为了一致性和准确性只能由一台主机进行执行,并且需要成功执行。
1.被动选择策略:宿主的被动选择机制一般可以随机或者按照顺序选择策略,也可以按照当前宿主机进行的任务执行数量的方式进行常规的调度分配。当然,也可以进行高级的操作,参照宿主机的处理能力(吞吐量和响应时间)、资源使用情况(CPU、Memory、Disk I/O、Net I/O等)进行反馈机制的动态分配。后者需要有集中节点存储当前宿主机的处理能力、资源情况,便于在决策选择中提供参照。
2.主动选择策略:宿主的主动选择具备更加丰富的选举策略,任务在下达到具体算子时,会比较明确的定义出当前任务需要由多少个宿主参与执行,通过zookeeper的分布式锁来实现锁的抢占机制,抢占成功则执行,否则放弃。这种选举策略让宿主机得到了更多的参与,降低了对调度器的依赖。这种主动选择的方式,避免被动选择因不具备执行条件被选中,在执行的能力在时间上的损耗。
2.3 任务故障转移
调度任务的从任务级别job到transformer、operator,整个链条都存在具体局部失败的情况,调度器需要在原目标宿主机重试和失败后转移到其他备宿主机的功能,最大力度的保证任务被成功执行。
2.4 执行算子抽象
以往单机任务的调度可以比较灵活的执行多样的任务,可以是脚本、Webservice调用、HDFS Client命令行等,但是对于分布式协作需要接收外部命令运行,这就需要算子通过标准的数据通讯协议对外提供调用服务,常规的WebService、RPC(thrift/protocol buffer)等协议在跨语言通讯上具有较为广泛的应用。所以具体执行单元可以是具体任务的抽象,例如提供了Rest API方式,调用的URL和参数都是执行方填入,最大程度上支撑了灵活性;数据库操作算子可以包含数据库验证信息、具体执行的SQL等。执行算子抽象后,满足规范和灵活性,灵活是一个双刃剑,可以最大限度的满足用户需求,但也会导致大数据层面无法很细粒度的去感知数据的表、字段数据的完成情况,对数据生产无法更加精细粒度的产出交付。
2.5 弹性扩展
任务具体执行的宿主机需要在调度层面满足弹性的扩展,扩展最主要的需要是满足高可用和任务随着水平扩展进行分摊压力。在集群目标宿主机选择时,一般目标集合可以指定具体IP-List,也可以是一个BNS(百度机器的NameServer服务)。IP-List方式设置比较简单直观,但是存在每次调整依赖变更调度系统服务,变更之后还需要进行刷新宿主机的情况。而通过BNS服务比较简单,同时和线上服务发布部署进行结合,不存在延迟部署和刷新,推荐通过BNS的方式介入。
2.6 触发机制
常规触发是按照执行间隔或者具体时间的Crontab语法,开始时间,截止时间参数完成,但是在分布式调度任务中,最重要的就是完成协作,所以如果要进阶的话,就是依赖触发的机制。这种就很好的形成了上下游依赖触发,是分布式协作的关键步骤。从最初的任务节点按照常规触发,下游节点形成依赖链条,这里如果在高级进阶的话,就是依赖的某个/某些频次触发,比如每小时的12分钟开始被执行,下游可以选择具体的2:12 ,4:12进行触发,而非每个整点12分都被调用。这三种方式目前在外卖的大数据平台都有不同场景诉求,架构设计在3个需求上都有灵活的交付。
2.7 堵塞机制
对于相同任务的不同时间的运行实例,会存在前面的实例还没有正常结束的情况,这种在高频次调用,第三方依赖故障延迟等情况下会出现,如果继续调用会造成调用链条恶化,所以防止这种情况,堵塞机制会提供三种模式:常规例行(默认模式)、丢弃后续、丢弃前例。后面2种方案都需要提供容错重放机制,这个场景比较类似1.1章节提到的结算案例。
2.8 图形化进展查看
调度可以根据调用链条和不同事件频次的实例,通过树状图形化的方式查看执行的进度情况,例如可以查看job中transformer、算子的运行机器状况、状态和具体的实时执行日志。图形化是根据调用的触发机制分析出来的一个链条,是在烦冗复杂的调用关系中找到清晰脉络的数据直观表达的方式,是调度中常规的展示方式。在进阶中可以查看相应的参数传递,并发算子的执行进度条,预估完成周期等。
2.9 报警
通过邮件或者短信的方式对不符合预期返回标识的进行中止,同时通过邮件或者短信等方式对预先设置的用户或者用户组发出警告。报警触发的机制可以在宿主机单台时候触发,也可以在一定占比的宿主机在一定的时间窗口超过了阈值,触发报警。同时也要支持报警的屏蔽,用在进行运维或者升级部署、运维接管的情况。
上面是很多常规调度拥有的一些特征,这些是在分布式场景下的延伸需求,从单点简单的逻辑到多节点的协作统筹在工程层面无疑增加了额外辅助,这些都是在业务演进中逐步完善起来,而高可用、高效率是在分布式环境下做出的改变。












