

4.敏捷大数据关键技术
大数据时代,各种新兴技术和计算框架层出不穷,加之分析需求的不断变化,如何使大数据架构能随时调整以适应业务需求,跟上技术更新的步伐,是大数据应用要解决的关键问题,这也是为什么提出敏捷大数据架构的本质原因。面对大型企业动辄数十个上百个信息系统,如何通过跨物理、虚拟、公共和私有云环境实现一致性、互操作性和可移植性,对IT基础设施来讲是极大的挑战。所以微服务和容器技术应运而生,微服务实现系统模块的组件化和独立自治运行,容器能实现轻量级的虚拟化,而且完全使用沙箱机制,相互之间没有任何接口。微服务、容器与云计算技术的天然结合,及其快速的研发、部署、维护优势,使得基于微服务和容器的敏捷大数据应用潜力巨大。
(1)微服务技术
服务的本质就是行为的抽象,面向对象的方法是从对象实体这个维度对世界进行描述,而面向服务(SOA)则是从行为模式这个维度对世界进行描述,本质上是两种不同维度的描述方法。
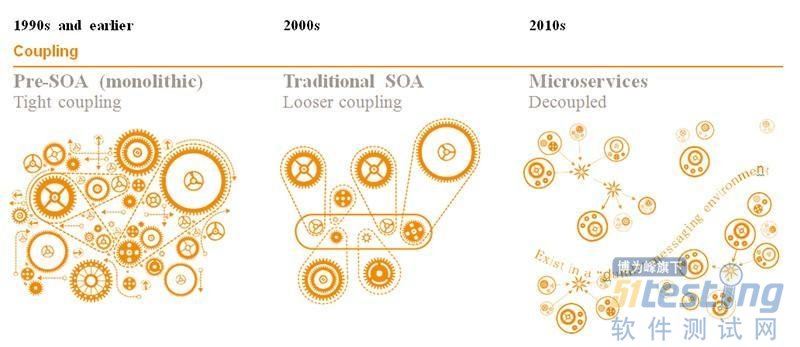
图6. 软件服务化发展历程
由于数据科学的迭代性本质,大数据分析即服务成为应用热点,而微服务与容器技术能有效支持本文提出的敏捷大数据SFV核心原则。近年来,微服务(设计思想发源于康威定律,如图7)成为互联网和大数据企业的研究和设计热点,诸如谷歌、亚马逊、Facebook、百度、京东、携程等公司都在采用微服务理论和技术进行产品的设计、研发和部署。Netflix公司的Adrian Cockcroft将微服务称为“细化SOA(Service Oriented Architecture, SOA)”,并认为这是一套具备开创意义的新型架构。敏捷之父Martin Fowler在他的《Micro services》一文中给出了微服务的定义,概括来说,微服务设计思想是一种使用若干小服务开发庞大应用的方法,每个服务运行在自己的进程中,通过轻量级的通信机制进行信息交互,每个微服务的粒度基于业务能力大小进行构建,并可以由不同的程序语言实现,构建的服务链能够通过容器等技术进行自动化部署。
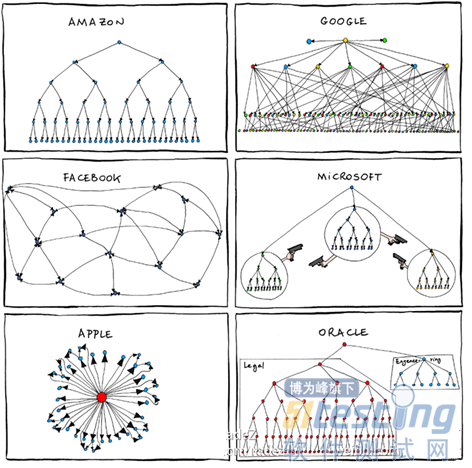
图7. 康威定律(Conway’s Law),系统的结构受限于设计这个系统的组织的沟通结构。由于系统的结构可能会随着设计的深入而变化,所以必须保持设计的精简与灵活。
从上述微服务定义可以看到,去中心化、原子化、独立自治、快速组合、自动部署等特性是微服务技术的核心要素,中心思想是将一个单体应用构架打散,把原来庞大的应用层功能切分成粒度较小的微服务模块,数据库也按微服务功能单元进行相应的拆分进行支持(如图8所示),采用基于云的容器技术单独运行这些服务模块,通过网络和轻量级通信机制将这些分解的服务模块协同连接起来,形成微服务簇和网络,完成大型复杂任务,这种通过将复杂系统切分成若干小的微服务模块的方式,其分布式、低耦合架构能极大地适应大数据分布式处理特性。
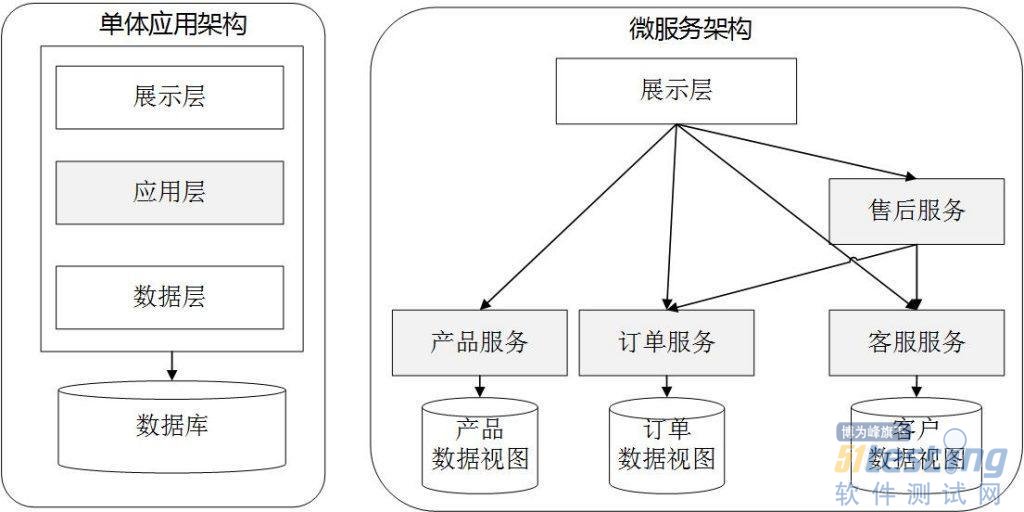
图8 传统单体应用架构与微服务架构的区别
(2)容器技术
微服务技术采用类似搭积木的构建方法,使得服务之间不相互影响,而且同一个系统的微服务可以采用不同的开发语言和数据库技术。但是面对大型企业动辄数十、上百个信息系统,如何通过跨物理、虚拟、公共和私有云环境实现一致性、互操作性和可移植性,对IT基础设施来讲是极大的挑战。所以容器技术应运而生,容器最早由Docker公司提出并应用于自家的PaaS云服务平台,近年来获得广泛认可,很多大型企业开始将单体应用系统微服务化,并部署在容器中。容器基于操作系统之上能实现相比传统虚拟化技术(如VMware)更轻量级的虚拟化,而且完全使用沙箱机制,相互之间没有接口。Hadoop的子系统Kubernetes已经能支持基于云计算和Docker容器技术的微服务开发和部署,容器技术与云计算的天然结合及其快速的研发、部署、维护优势,对于微服务和敏捷大数据架构的设计和实现具有重要支撑作用。
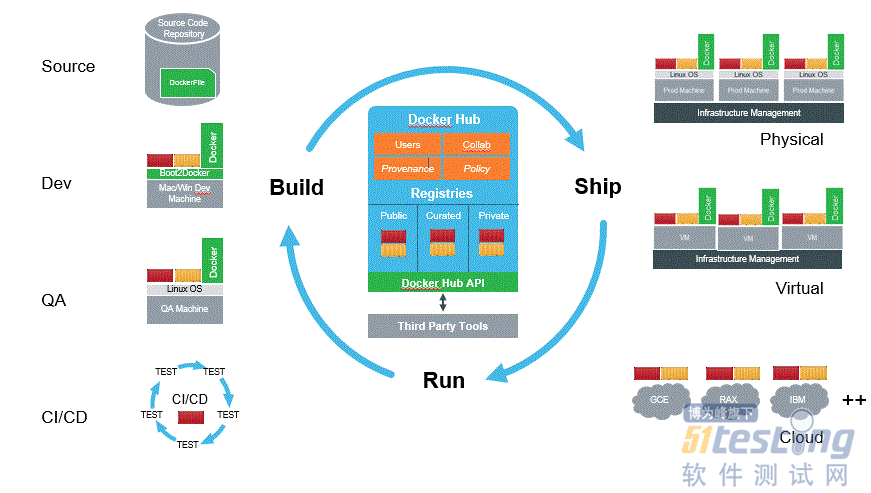
图9 Docker容器架构图
(3)数据融合技术
由于大数据呈现的关联性、动态性、多源异构性等特点,导致大数据的存储、挖掘、分析和理解面临极大挑战。如何对多种形态格式的数据进行统一标准化融合处理,是敏捷大数据要解决的关键问题。与一般的大数据融合目标不同,本文主要从构建标准数据集的角度进行大数据多粒度融合,通过构建统一数据单元(unified data units,UDU)来支持多模态特征融合和多种类型、结构数据集的封装融合。将多源异构数据进行抽取、融合、集成为支持不同计算模型处理的UDU数据集,是多粒度信息融合技术的核心目标。统一数据单元是独立的和灵活的实体数据集,可随数据源和分析需求的变化进行快速重组、调整和更新。通过信息融合形成的UDU标准数据集,是进行敏捷大数据处理的基础。
针对机器学习各类模型的数据适配特点,我们提出了一种标准数据集定义:统一数据单元(UDU)对大数据多个层次和粒度的信息进行融合处理。特别是对多模态数据,通过统一数据单元设计方法能实现数据的存储优化和机器学习模型数据输入的标准化,以统一数据单元作为敏捷大数据系统的基本数据组织和处理单元,能提高大数据分析模型和算法的适应性和敏捷性,提升大数据处理能力。多粒度信息融合设计如下图所示。
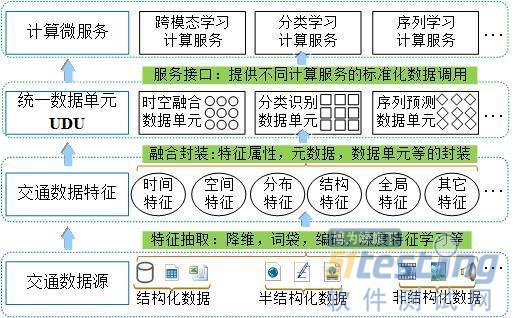
图10 大数据多粒度信息融合设计
上图的UDU统一数据单元至少可以支持三个层面的大数据融合,一是特征级融合,支持跨模态特征(如时间+空间特征)的大数据计算模型处理;二是数据级融合,支持多维数据立方体(Data Cube),数据集市(星型,雪花型模式)等数据模式和数据结构的融合;三是模型级融合,从不同模型任务(如分类、聚类、预测、关联等模型)角度支持相应的数据单元处理。设计和构造大数据统一数据单元,需进行如下三个环节的处理。
1)特征抽取:对结构化数据、半结构化数据和非结构化数据进行数据集成和特征抽取,抽取出数据中的各类不同特征,包括时间特征、空间特征或其他全局特征等,实现对数据相关的位置属性、时间空间关联属性和其他观测属性等的特征描述。2)融合封装:抽取出来的各类数据特征,或者初步预处理后的数据,根据不同的计算模型数据处理特点和要求,封装成结构和格式统一的数据处理单元,形成标准分析数据集,为上层的挖掘计算服务提供快速数据适配。可以通过元数据定义方法和XML/JSON等技术,实现不同种类的统一数据单元定义,对每类统一数据单元进行基本信息和各类属性定义和描述,包括标识ID、基本属性、语义属性、结构属性等内容。3)服务接口:封装好的统一数据单元数据集,针对不同的挖掘计算服务模型实现快速数据适配,设计统一的数据单元调用接口,通过接口定义和参数设置对封装数据单元进行解析,并对数据集各类属性特征、结构信息等进行提取。
5.敏捷大数据系统架构
根据上述敏捷大数据关键技术的分析,如何设计实现有效的敏捷大数据系统架构是敏捷大数据应用的重点内容。下面以交通大数据处理为例,对其敏捷处理架构进行了初步设计。由于交通大数据的复杂性和分析目标的多样性,对传统的数据挖掘分析模式和大数据技术架构提出了挑战。例如,针对海量交通历史静态数据,需采用离线批处理技术,而动态实时流交通数据则需要流式计算框架进行处理。另外,对文本、图像、视频、传感器等多模态数据需采用不同的机器学习模型进行处理,如何进行跨模态的融合计算分析也是应用难点。针对交通大数据分析需求的变更和扩展,大数据系统如何进行快速响应和功能、模型的扩充和调整,是面向交通的敏捷大数据架构设计要解决的关键问题。
换句话说,要能根据不同的交通大数据分析需求设计灵活的处理架构进行支持,大数据架构要能从采集、存储、计算、应用多个层面,满足不同分析需求的变更或扩张。基于敏捷大数据方法论及其关键技术的分析和研究,从数据采集集成、大规模数据存储和数据融合、多模式/多模态计算微服务、数据应用4个层面进行了敏捷大数据架构设计。通过基于多粒度大数据集成融合构建统一数据单元,形成标准数据集,通过基于微服务的计算模型抽象和汇聚层处理,实现交通大数据挖掘的敏捷化、服务化。采用标准接口和插件开发的方式,对大数据主流处理框架(如Hadoop、Spark、Storm等)能进行统一配置管理,基于即插即用的构件化和服务化设计,各层子系统和组件可根据分析目标进行快速选型、灵活配置,构建原型和迭代升级(如下图中根据两条虚线不同的设计路径,可以快速配置实现历史数据库数据的批处理分析,或公网采集数据的流处理分析),敏捷大数据总体架构设计如下图所示。
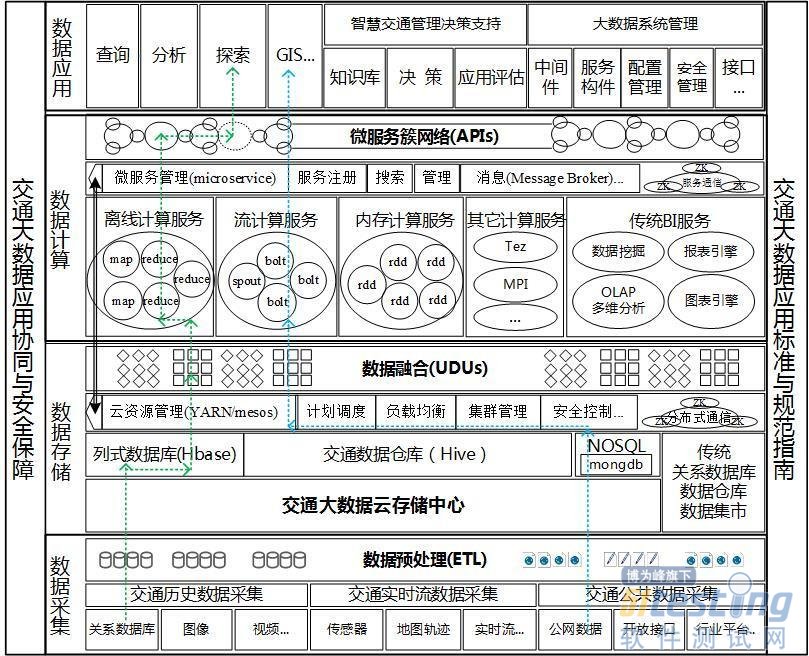
图11 面向交通的敏捷大数据总体架构设计
1)数据采集层:分3个层面的采集技术进行支持,一是传统业务系统数据库和半结构化、结构化数据的采集和集成,如采用Sqoop技术进行关系数据库和Hadoop系统之间的数据抽取和交换;二是交通实时流数据的采集,包括实时传感器数据、定位轨迹数据和其他实时流数据;三是交通公共数据的采集,包括公网的数据爬取、开放平台的数据接口、行业公共数据库的数据交换等。对采集到的数据需进行提取、转换和加载(extract-transform-load,ETL)处理,包括数据抽取、转换、清洗和隐私脱敏等预处理工作,预处理集成后的数据进入交通大数据云存储中心。
2)数据存储层:交通领域数据规模巨大,数据存储层需设计基于云计算的分布式云存储系统,以支持海量数据的存储扩展。提供基于云的列式存储、NoSQL存储或数据仓库存储能力;根据业务需求和快速配置,可切换相应的分布式存储模式,还可根据需要对传统BI系统的数据仓库和数据集市进行集成。利用Hadoop集群提供PB级存储能力扩展,同时Hadoop YARN 和Spark Mesos等集群资源管理框架可支持多种存储模式和计算模式(主要对存储和计算两个层面资源进行管理,如图中双向箭头所示)的云资源调度。在此基础上,对各类存储数据进行多粒度信息融合,构建统一数据处理单元,为计算服务层提供标准化的分析数据集。
3)数据计算层:针对交通大数据多源、异构、海量等特征,传统的计算模型难以直接处理。数据计算层需满足主流大数据处理框架的各种计算模型与方法实现,如基于云计算并行框架,实现基于Hadoop批处理、Storm流处理、Spark内存处理的高效数据挖掘与机器学习。数据计算层采用基于统一数据处理单元和计算模式、模型微服务化的大数据分析框架,通过构建多种微服务簇网络(主要分计算微服务、数据微服务和流程微服务,涵盖存储和计算两个层面,如图中双向箭头所示),为应用层提供支持MapReduce、Storm、Spark等多种计算模式下的多种数据挖掘模型与方法(如分类、聚类、序列等);根据大数据分析需求和数据特征,可基于组件配置和服务治理技术进行各类服务的快速切换和灵活管理。
4)数据应用层:数据应用层首先要满足智慧交通各类大数据分析需求,包括基本的可视化与查询、展示、探索等,分析结果能结合知识库应用于决策支持。另外,大数据系统本身管理方面,针对构件化和微服务设计,需对相关中间件进行设计,实现服务治理、组件配置、安全、接口等功能,以支撑存储层和计算层各类微服务的敏捷管理。
敏捷大数据架构的关键内容除了数据融合UDU层面之外,另外一个关键环节就是对多种计算模式框架、多种计算模型的微服务化设计,包括计算框架、模型和算法的微服务化、数据获取调用的微服化和分析流程的微服务化等层面。其核心是计算微服务,如MapReduce批处理服务、Storm流处理服务、Spark内存处理服务,每种大的计算框架微服务下包含具体挖掘模型等小粒度的计算微服务支持(如分类模型服务、序列模型服务)等。由于微服务详细技术涉及面比较广,包括微服务的注册、定位、发现和搜索(基于分布式一致算法Paxos和Zookeeper框架等),微服务的轻量级通信机制如REST(Representational State Transfer)、RPC(Remote Procedure Call Protocol)、IPC(Inter-Process Communication)等,微服务的容错处理(熔断、限流、负载均衡等),微服务容器化和服务的测试、部署等方面。由于篇幅原因,各方面的技术细节这里不做赘述,大家可以参考专业数据进行了解。在敏捷大数据架构和数据融合统一数据单元基础上,进行了大数据分析层的微服务设计,如下图。
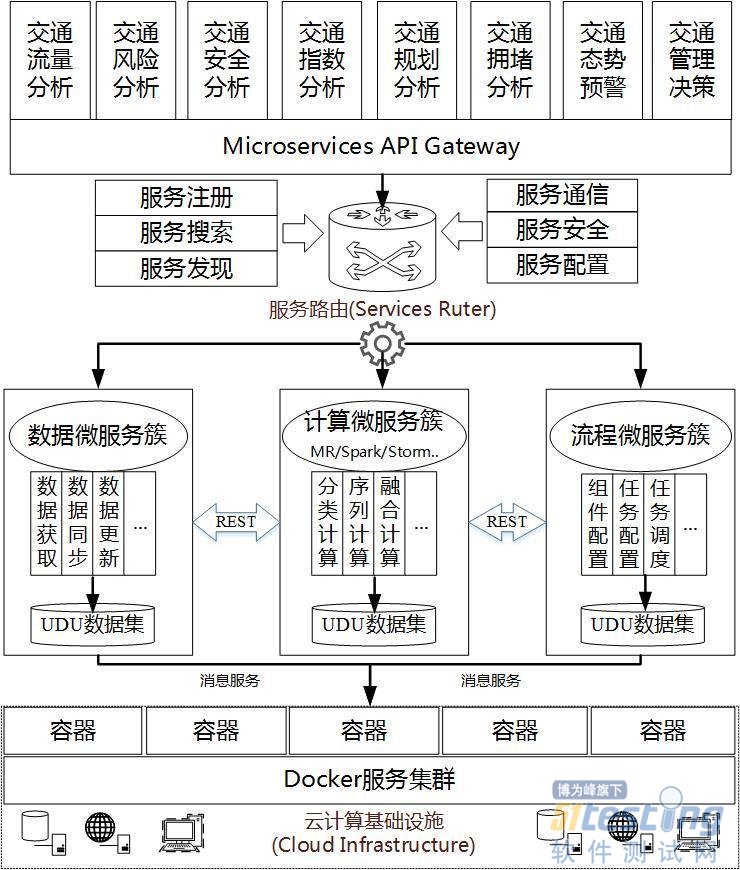
图12 面向交通的大数据分析微服务化设计
大数据分析微服务化的核心理念是一个服务只专注做好一类或一个分析,服务的粒度和分析功能大小、边界要匹配,服务方(计算微服务)和消费方(基于微服务的分析功能)要能解耦,即调整或升级一个微服务不能影响其他微服务。大数据分析微服务设计主要内容包括如下几个方面。
1)大数据分析业务抽象和微服务划分:按多模式计算框架分,有MapReduce批处理框架、Storm流式处理框架、Spark内存处理框架、图计算框架等;按挖掘模型分,有分类、聚类、序列、多模态、多任务等不同种类计算模型。针对交通大数据各类分析需求和数据处理特点,进行大数据业务分析和抽象建模,并选择相应的计算模型和计算框架进行支撑,再决定需要哪些微服务,并实现微服务的划分和组合,设定好微服务网络的总体设计目标,并通过统一的微服务接口(Microservices API Gateway)进行调用。
2)微服务簇设计及契约接口定义:针对大数据处理特点,服务层中的微服务分3类进行规划设计,数据微服务簇负责从UDU标准数据集中进行数据获取、数据同步和更新等操作;计算微服务簇是敏捷大数据处理的核心,按多模式计算框架和多类计算模型两个维度进行挖掘分析服务的统筹设计;流程微服务簇负责数据微服务、计算微服务的协同处理,同时对系统组件的配置管理和调度进行支持。各类微服务通过REST、RPC等轻量级通信机制和MessageBroker等消息服务进行交互和联系[14],构建微服务簇网络,并通过服务路由进行统一管理和调度。
3)微服务治理和容器部署:由各类微服务簇连接成的微服务网络,其高效协调工作离不开微服务治理技术和容器管理技术。通过服务路由和服务治理负责各种大小微服务的注册、搜索、发现、通信和统一配置,最后基于云计算和容器技术进行微服务的自动部署和动态管理。
6.敏捷大数据应用评述
本文提出的敏捷大数据架构在一定程度上实现了大数据融合处理和挖掘计算的服务化、标准化和流程化。基于统一数据单元和计算、流程微服务设计思想,对微服务的构建和管理进行快速实现,通过各种微服务的划分、组合、编排和动态配置,能构建模块化、可配置、可复用、可扩展的敏捷大数据分析系统。相比传统大数据处理架构,敏捷大数据架构在如下几个方面具有明显优势(见表1)。

表1 敏捷大数据架构与传统大数据架构比较分析
从上述各项特性的比较分析可以看到,敏捷大数据架构除了支持大规模数据增长之外,更重要的是能适应大数据分析业务的扩展和变化,通过容器和服务化技术,具备高容错性和稳定性,能支持大数据分析的失败处理和自动恢复等,能在海量数据条件下快速完成多种计算模型和分析处理,能基于数据融合单元和计算服务化技术,支持多模态计算和多模式计算任务处理,能在有限的成本条件下提高大数据分析效率。
当然要实现一套有效的敏捷大数据架构,不同的业务需求或采用不同的技术路线,所做的工作可能有较大差异,所以本文的标题定义为方法论。条条大路通罗马,技术只是工具,关键还是方法论和指导思想。另外在架构详细设计和实现方面,还有几个难点需要突破,由于大数据计算框架众多、每种框架下所支持的分析模型也很多、可视化库更多…这些计算框架的技术架构和开发语言、接口定义标准可能都不一样,敏捷大数据架构如何通过构建化、插件化等技术对上述工具集进行标准化和流程化的快速集成,这是敏捷实现要解决的主要问题。
我们结合正在规划建设的综合交通大数据分析云服务平台,以本文提出的敏捷大数据方法论及架构设计,作为关键技术选型和技术路线实现的指导思想,并进行了初步应用。综合交通大数据分析云服务平台的主要目标是通过大数据技术解决交通资源的供需智能匹配和瓶颈预测分析问题。应用多粒度信息融合和多模态计算微服务技术,对交通大数据进行集成、融合和挖掘;采用定量分析和定性分析相结合的机器学习进行供求配置预测,为智能出行推荐、交通枢纽瓶颈分析、多模接驳换乘、实时交通管控等智慧交通关键环节提供大数据分析和决策支持。由于综合交通大数据多源异构、时空关联和动态处理等特点,传统大数据架构面临扩展性、兼容性、稳定性诸多问题。基于敏捷大数据方法论,设计了面向智慧交通的具有构件化、云服务化、容器化特性的敏捷大数据架构,为综合交通大数据分析云服务平台的研发提供了切实参考和应用指导,并在一定程度上提高了开发效率和控制了技术风险。
7.总结与展望
探讨了大数据应用落地的主要瓶颈和面临的挑战。针对大数据特点及其分析瓶颈问题,分析了传统信息化技术架构与大数据系统架构的区别,基于敏捷、精益和迭代设计思想,首次提出了敏捷大数据方法论,并对其概念定义、核心要素、流程优化和关键技术等内容进行了论述,通过分析敏捷大数据的设计缘由,基于传统数据挖掘流程改进,设计了面向微服务的敏捷大数据处理流程,并对其关键支撑技术进行了初步研究和探索。构建了基于微服务和多粒度信息融合技术的敏捷大数据架构,并结合实际案例对交通大数据微服务化、交通大数据融合等关键技术环节进行了详细设计和论述。
敏捷大数据的提出是基于数据科学迭代性本质,为各行业大数据应用环境下的高效、灵活大数据系统建设和机器学习、知识发现提供了新方法、新思路和新的技术架构,希望能通过敏捷设计最大程度降低成本、控制风险,从而发挥出大数据的应用价值,相比传统大数据处理方法和技术架构,本方法论的重要意义和参考价值不言而喻。当然,敏捷大数据作为一个新的涵盖多种前沿信息技术的跨领域应用研究问题,还需要在设计方法、关键技术和系统架构等方面进行深入探索和应用实践。












