

Gulp插件的测试
现在前端构建使用最多的就是Gulp了,它简明的API、流式构建理念、以及在内存中操作的性能,让它备受追捧。虽然现在有像webpack这样的后起之秀,但Gulp依旧凭借着其繁荣的生态圈担当着前端构建的绝对主力。目前天猫前端就是使用Gulp作为代码构建工具。
用了Gulp作为构建工具,也就免不了要开发Gulp插件来满足业务定制化的构建需求,构建过程本质上其实是对源代码进行修改,如果修改过程中出现bug很可能直接导致线上故障。因此针对Gulp插件,尤其是会修改源代码的Gulp插件一定要做仔细的测试来保证质量。
又一个煎蛋的栗子
比如这里有个煎蛋的Gulp插件,功能就是往所有js代码前加一句注释// 天猫前端招人,有意向的请发送简历至lingyucoder@gmail.com,Gulp插件的代码大概就是这样:
'use strict'; const _ = require('lodash'); const through = require('through2'); const PluginError = require('gulp-util').PluginError; const DEFAULT_CONFIG = {}; module.exports = config => { config = _.defaults(config || {}, DEFAULT_CONFIG); return through.obj((file, encoding, callback) => { if (file.isStream()) return callback(new PluginError('gulp-welcome-to-tmall', `Stream is not supported`)); file.contents = new Buffer(`// 天猫前端招人,有意向的请发送简历至lingyucoder@gmail.com\n${file.contents.toString()}`); callback(null, file); }); }; |
对于这么一段代码,怎么做测试呢?
一种方式就是直接伪造一个文件传入,Gulp内部实际上是通过vinyl-fs从操作系统读取文件并做成虚拟文件对象,然后将这个虚拟文件对象交由through2创造的Transform来改写流中的内容,而外层任务之间通过orchestrator控制,保证执行顺序(如果不了解可以看看这篇翻译文章Gulp思维——Gulp高级技巧)。当然一个插件不需要关心Gulp的任务管理机制,只需要关心传入一个vinyl对象能否正确处理。因此只需要伪造一个虚拟文件对象传给我们的Gulp插件就可以了。
首先设计测试用例,考虑两个主要场景:
虚拟文件对象是流格式的,应该抛出错误
虚拟文件对象是Buffer格式的,能够正常对文件内容进行加工,加工完的文件加上// 天猫前端招人,有意向的请发送简历至lingyucoder@gmail.com的头
对于第一个测试用例,我们需要创建一个流格式的vinyl对象。而对于各第二个测试用例,我们需要创建一个Buffer格式的vinyl对象。
当然,首先我们需要一个被加工的源文件,放到test/src/testfile.js下吧:
'use strict'; console.log('hello world'); |
这个源文件非常简单,接下来的任务就是把它分别封装成流格式的vinyl对象和Buffer格式的vinyl对象。
构建Buffer格式的虚拟文件对象
构建一个Buffer格式的虚拟文件对象可以用vinyl-fs读取操作系统里的文件生成vinyl对象,Gulp内部也是使用它,默认使用Buffer:
'use strict'; require('should'); const path = require('path'); const vfs = require('vinyl-fs'); const welcome = require('../index'); describe('welcome to Tmall', function() { it('should work when buffer', done => { vfs.src(path.join(__dirname, 'src', 'testfile.js')) .pipe(welcome()) .on('data', function(vf) { vf.contents.toString().should.be.eql(`// 天猫前端招人,有意向的请发送简历至lingyucoder@gmail.com\n'use strict';\nconsole.log('hello world');\n`); done(); }); }); }); |
这样测了Buffer格式后算是完成了主要功能的测试,那么要如何测试流格式呢?
构建流格式的虚拟文件对象
方案一和上面一样直接使用vinyl-fs,增加一个参数buffer: false即可:
把代码修改成这样:
'use strict'; require('should'); const path = require('path'); const vfs = require('vinyl-fs'); const PluginError = require('gulp-util').PluginError; const welcome = require('../index'); describe('welcome to Tmall', function() { it('should work when buffer', done => { // blabla }); it('should throw PluginError when stream', done => { vfs.src(path.join(__dirname, 'src', 'testfile.js'), { buffer: false }) .pipe(welcome()) .on('error', e => { e.should.be.instanceOf(PluginError); done(); }); }); }); |
这样vinyl-fs直接从文件系统读取文件并生成流格式的vinyl对象。
如果内容并不来自于文件系统,而是来源于一个已经存在的可读流,要怎么把它封装成一个流格式的vinyl对象呢?
这样的需求可以借助vinyl-source-stream:
'use strict'; require('should'); const fs = require('fs'); const path = require('path'); const source = require('vinyl-source-stream'); const vfs = require('vinyl-fs'); const PluginError = require('gulp-util').PluginError; const welcome = require('../index'); describe('welcome to Tmall', function() { it('should work when buffer', done => { // blabla }); it('should throw PluginError when stream', done => { fs.createReadStream(path.join(__dirname, 'src', 'testfile.js')) .pipe(source()) .pipe(welcome()) .on('error', e => { e.should.be.instanceOf(PluginError); done(); }); }); }); |
这里首先通过fs.createReadStream创建了一个可读流,然后通过vinyl-source-stream把这个可读流包装成流格式的vinyl对象,并交给我们的插件做处理
Gulp插件执行错误时请抛出PluginError,这样能够让gulp-plumber这样的插件进行错误管理,防止错误终止构建进程,这在gulp watch时非常有用
模拟Gulp运行
我们伪造的对象已经可以跑通功能测试了,但是这数据来源终究是自己伪造的,并不是用户日常的使用方式。如果采用最接近用户使用的方式来做测试,测试结果才更加可靠和真实。那么问题来了,怎么模拟真实的Gulp环境来做Gulp插件的测试呢?
首先模拟一下我们的项目结构:
test ├── build │ └── testfile.js ├── gulpfile.js └── src └── testfile.js |
一个简易的项目结构,源码放在src下,通过gulpfile来指定任务,构建结果放在build下。按照我们平常使用方式在test目录下搭好架子,并且写好gulpfile.js:
'use strict'; const gulp = require('gulp'); const welcome = require('../index'); const del = require('del'); gulp.task('clean', cb => del('build', cb)); gulp.task('default', ['clean'], () => { return gulp.src('src/**/*') .pipe(welcome()) .pipe(gulp.dest('build')); }); |
接着在测试代码里来模拟Gulp运行了,这里有两种方案:
使用child_process库提供的spawn或exec开子进程直接跑gulp命令,然后测试build目录下是否是想要的结果
直接在当前进程获取gulpfile中的Gulp实例来运行Gulp任务,然后测试build目录下是否是想要的结果
开子进程进行测试有一些坑,istanbul测试代码覆盖率时时无法跨进程的,因此开子进程测试,首先需要子进程执行命令时加上istanbul,然后还需要手动去收集覆盖率数据,当开启多个子进程时还需要自己做覆盖率结果数据合并,相当麻烦。
那么不开子进程怎么做呢?可以借助run-gulp-task这个工具来运行,其内部的机制就是首先获取gulpfile文件内容,在文件尾部加上module.exports = gulp;后require gulpfile从而获取Gulp实例,然后将Gulp实例递交给run-sequence调用内部未开放的APIgulp.run来运行。
我们采用不开子进程的方式,把运行Gulp的过程放在before钩子中,测试代码变成下面这样:
'use strict'; require('should'); const path = require('path'); const run = require('run-gulp-task'); const CWD = process.cwd(); const fs = require('fs'); describe('welcome to Tmall', () => { before(done => { process.chdir(__dirname); run('default', path.join(__dirname, 'gulpfile.js')) .catch(e => e) .then(e => { process.chdir(CWD); done(e); }); }); it('should work', function() { fs.readFileSync(path.join(__dirname, 'build', 'testfile.js')).toString().should.be.eql(`// 天猫前端招人,有意向的请发送简历至lingyucoder@gmail.com\n'use strict';\nconsole.log('hello world');\n`); }); }); |
这样由于不需要开子进程,代码覆盖率测试也可以和普通Node.js模块一样了
测试命令行输出
双一个煎蛋的栗子
当然前端写工具并不只限于Gulp插件,偶尔还会写一些辅助命令啥的,这些辅助命令直接在终端上运行,结果也会直接展示在终端上。比如一个简单的使用commander实现的命令行工具:
// in index.js 'use strict'; const program = require('commander'); const path = require('path'); const pkg = require(path.join(__dirname, 'package.json')); program.version(pkg.version) .usage('[options] <file>') .option('-t, --test', 'Run test') .action((file, prog) => { if (prog.test) console.log('test'); }); module.exports = program; // in bin/cli #!/usr/bin/env node 'use strict'; const program = require('../index.js'); program.parse(process.argv); !program.args[0] && program.help(); // in package.json { "bin": { "cli-test": "./bin/cli" } } |
拦截输出
要测试命令行工具,自然要模拟用户输入命令,这一次依旧选择不开子进程,直接用伪造一个process.argv交给program.parse即可。命令输入了问题也来了,数据是直接console.log的,要怎么拦截呢?
这可以借助sinon来拦截console.log,而且sinon非常贴心的提供了mocha-sinon方便测试用,这样test.js大致就是这个样子:
'use strict'; require('should'); require('mocha-sinon'); const program = require('../index'); const uncolor = require('uncolor'); describe('cli-test', () => { let rst; beforeEach(function() { this.sinon.stub(console, 'log', function() { rst = arguments[0]; }); }); it('should print "test"', () => { program.parse([ 'node', './bin/cli', '-t', 'file.js' ]); return uncolor(rst).trim().should.be.eql('test'); }); }); |
PS:由于命令行输出时经常会使用colors这样的库来添加颜色,因此在测试时记得用uncolor把这些颜色移除
小结
Node.js相关的单元测试就扯这么多了,还有很多场景像服务器测试什么的就不扯了,因为我不会。当然前端最主要的工作还是写页面,接下来扯一扯如何对页面上的组件做测试。
页面测试
对于浏览器里跑的前端代码,做测试要比Node.js模块要麻烦得多。Node.js模块纯js代码,使用V8运行在本地,测试用的各种各样的依赖和工具都能快速的安装,而前端代码不仅仅要测试js,CSS等等,更麻烦的事需要模拟各种各样的浏览器,比较常见的前端代码测试方案有下面几种:
构建一个测试页面,人肉直接到虚拟机上开各种浏览器跑测试页面(比如公司的f2etest)。这个方案的缺点就是不好做代码覆盖率测试,也不好持续化集成,同时人肉工作较多
使用PhantomJS构建一个伪造的浏览器环境跑单元测试,好处是解决了代码覆盖率问题,也可以做持续集成。这个方案的缺点是PhantomJS毕竟是Qt的webkit,并不是真实浏览器环境,PhantomJS也有各种各样兼容性坑
通过Karma调用本机各种浏览器进行测试,好处是可以跨浏览器做测试,也可以测试覆盖率,但持续集成时需要注意只能开PhantomJS做测试,毕竟集成的Linux环境不可能有浏览器。这可以说是目前看到的最好的前端代码测试方式了
这里以gulp为构建工具做测试,后面在React组件测试部分再介绍以webpack为构建工具做测试
叒一个煎蛋的栗子
前端代码依旧是js,一样可以用Mocha+Should.js来做单元测试。打开node_modules下的Mocha和Should.js,你会发现这些优秀的开源工具已经非常贴心的提供了可在浏览器中直接运行的版本:mocha/mocha.js和should/should.min.js,只需要把他们通过script标签引入即可,另外Mocha还需要引入自己的样式mocha/mocha.css
首先看一下我们的前端项目结构:
. ├── gulpfile.js ├── package.json ├── src │ └── index.js └── test ├── test.html └── test.js |
比如这里源码src/index.js就是定义一个全局函数:
window.render = function() { var ctn = document.createElement('div'); ctn.setAttribute('id', 'tmall'); ctn.appendChild(document.createTextNode('天猫前端招人,有意向的请发送简历至lingyucoder@gmail.com')); document.body.appendChild(ctn); } |
而测试页面test/test.html大致上是这个样子:
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <link rel="stylesheet" href="../node_modules/mocha/mocha.css"/> <script src="../node_modules/mocha/mocha.js"></script> <script src="../node_modules/should/should.js"></script> </head> <body> <div id="mocha"></div> <script src="../src/index.js"></script> <script src="test.js"></script> </body> </html> |
head里引入了测试框架Mocha和断言库Should.js,测试的结果会被显示在<div id="mocha"></div>这个容器里,而test/test.js里则是我们的测试的代码。
前端页面上测试和Node.js上测试没啥太大不同,只是需要指定Mocha使用的UI,并需要手动调用mocha.run():
mocha.ui('bdd'); describe('Welcome to Tmall', function() { before(function() { window.render(); }); it('Hello', function() { document.getElementById('tmall').textContent.should.be.eql('天猫前端招人,有意向的请发送简历至lingyucoder@gmail.com'); }); }); mocha.run(); |
在浏览器里打开test/test.html页面,就可以看到效果了:

在不同的浏览器里打开这个页面,就可以看到当前浏览器的测试了。这种方式能兼容最多的浏览器,当然要跨机器之前记得把资源上传到一个测试机器都能访问到的地方,比如CDN。
测试页面有了,那么来试试接入PhantomJS吧
使用PhantomJS进行测试
PhantomJS是一个模拟的浏览器,它能执行js,甚至还有webkit渲染引擎,只是没有浏览器的界面上渲染结果罢了。我们可以使用它做很多事情,比如对网页进行截图,写爬虫爬取异步渲染的页面,以及接下来要介绍的——对页面做测试。
当然,这里我们不是直接使用PhantomJS,而是使用mocha-phantomjs来做测试。npm install --save-dev mocha-phantomjs安装完成后,就可以运行命令./node_modules/.bin/mocha-phantomjs ./test/test.html来对上面那个test/test.html的测试了:

单元测试没问题了,接下来就是代码覆盖率测试
覆盖率打点
首先第一步,改写我们的gulpfile.js:
'use strict'; const gulp = require('gulp'); const istanbul = require('gulp-istanbul'); gulp.task('test', function() { return gulp.src(['src/**/*.js']) .pipe(istanbul({ coverageVariable: '__coverage__' })) .pipe(gulp.dest('build-test')); }); |
这里把覆盖率结果保存到__coverage__里面,把打完点的代码放到build-test目录下,比如刚才的src/index.js的代码,在运行gulp test后,会生成build-test/index.js,内容大致是这个样子:
var __cov_WzFiasMcIh_mBvAjOuQiQg = (Function('return this'))(); if (!__cov_WzFiasMcIh_mBvAjOuQiQg.__coverage__) { __cov_WzFiasMcIh_mBvAjOuQiQg.__coverage__ = {}; } __cov_WzFiasMcIh_mBvAjOuQiQg = __cov_WzFiasMcIh_mBvAjOuQiQg.__coverage__; if (!(__cov_WzFiasMcIh_mBvAjOuQiQg['/Users/lingyu/gitlab/dev/mui/test-page/src/index.js'])) { __cov_WzFiasMcIh_mBvAjOuQiQg['/Users/lingyu/gitlab/dev/mui/test-page/src/index.js'] = {"path":"/Users/lingyu/gitlab/dev/mui/test-page/src/index.js","s":{"1":0,"2":0,"3":0,"4":0,"5":0},"b":{},"f":{"1":0},"fnMap":{"1":{"name":"(anonymous_1)","line":1,"loc":{"start":{"line":1,"column":16},"end":{"line":1,"column":27}}}},"statementMap":{"1":{"start":{"line":1,"column":0},"end":{"line":6,"column":1}},"2":{"start":{"line":2,"column":2},"end":{"line":2,"column":42}},"3":{"start":{"line":3,"column":2},"end":{"line":3,"column":34}},"4":{"start":{"line":4,"column":2},"end":{"line":4,"column":85}},"5":{"start":{"line":5,"column":2},"end":{"line":5,"column":33}}},"branchMap":{}}; } __cov_WzFiasMcIh_mBvAjOuQiQg = __cov_WzFiasMcIh_mBvAjOuQiQg['/Users/lingyu/gitlab/dev/mui/test-page/src/index.js']; __cov_WzFiasMcIh_mBvAjOuQiQg.s['1']++;window.render=function(){__cov_WzFiasMcIh_mBvAjOuQiQg.f['1']++;__cov_WzFiasMcIh_mBvAjOuQiQg.s['2']++;var ctn=document.createElement('div');__cov_WzFiasMcIh_mBvAjOuQiQg.s['3']++;ctn.setAttribute('id','tmall');__cov_WzFiasMcIh_mBvAjOuQiQg.s['4']++;ctn.appendChild(document.createTextNode('天猫前端招人\uFF0C有意向的请发送简历至lingyucoder@gmail.com'));__cov_WzFiasMcIh_mBvAjOuQiQg.s['5']++;document.body.appendChild(ctn);}; |
这都什么鬼!不管了,反正运行它就好。把test/test.html里面引入的代码从src/index.js修改为build-test/index.js,保证页面运行时使用的是编译后的代码。
编写钩子
运行数据会存放到变量__coverage__里,但是我们还需要一段钩子代码在单元测试结束后获取这个变量里的内容。把钩子代码放在test/hook.js下,里面内容这样写:
'use strict'; var fs = require('fs'); module.exports = { afterEnd: function(runner) { var coverage = runner.page.evaluate(function() { return window.__coverage__; }); if (coverage) { console.log('Writing coverage to coverage/coverage.json'); fs.write('coverage/coverage.json', JSON.stringify(coverage), 'w'); } else { console.log('No coverage data generated'); } } }; |
这样准备工作工作就大功告成了,执行命令./node_modules/.bin/mocha-phantomjs ./test/test.html --hooks ./test/hook.js,可以看到如下图结果,同时覆盖率结果被写入到coverage/coverage.json里面了。
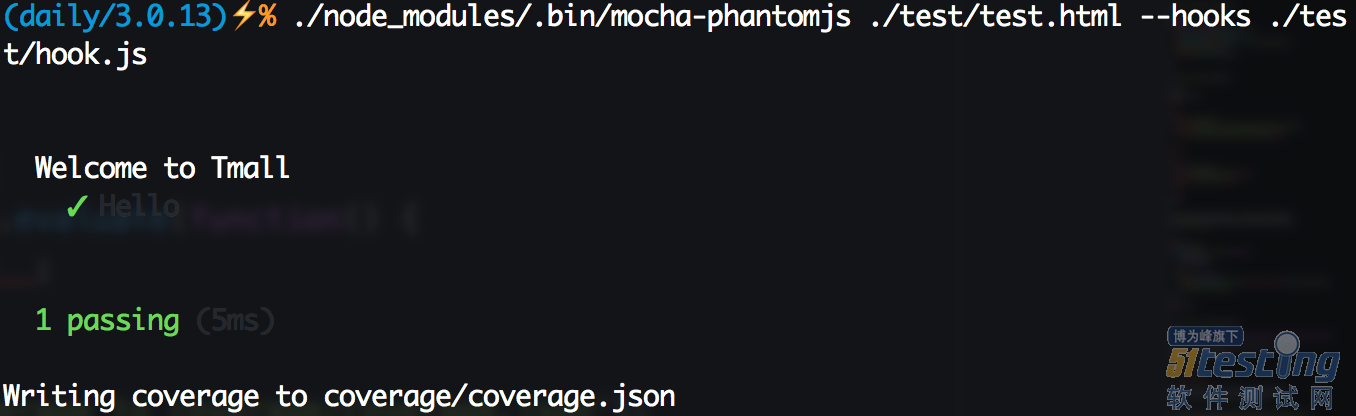
生成页面
有了结果覆盖率结果就可以生成覆盖率页面了,首先看看覆盖率概况吧。执行命令./node_modules/.bin/istanbul report --root coverage text-summary,可以看到下图:

还是原来的配方,还是想熟悉的味道。接下来运行./node_modules/.bin/istanbul report --root coverage lcov生成覆盖率页面,执行完后open coverage/lcov-report/index.html,点击进入到src/index.js:

一颗赛艇!这样我们对前端代码就能做覆盖率测试了
接入Karma
Karma是一个测试集成框架,可以方便地以插件的形式集成测试框架、测试环境、覆盖率工具等等。Karma已经有了一套相当完善的插件体系,这里尝试在PhantomJS、Chrome、FireFox下做测试,首先需要使用npm安装一些依赖:
karma:框架本体
karma-mocha:Mocha测试框架
karma-coverage:覆盖率测试
karma-spec-reporter:测试结果输出
karma-phantomjs-launcher:PhantomJS环境
phantomjs-prebuilt: PhantomJS最新版本
karma-chrome-launcher:Chrome环境
karma-firefox-launcher:Firefox环境
安装完成后,就可以开启我们的Karma之旅了。还是之前的那个项目,我们把该清除的清除,只留下源文件和而是文件,并增加一个karma.conf.js文件:
. ├── karma.conf.js ├── package.json ├── src │ └── index.js └── test └── test.js |
karma.conf.js是Karma框架的配置文件,在这个例子里,它大概是这个样子:
'use strict'; module.exports = function(config) { config.set({ frameworks: ['mocha'], files: [ './node_modules/should/should.js', 'src/**/*.js', 'test/**/*.js' ], preprocessors: { 'src/**/*.js': ['coverage'] }, plugins: ['karma-mocha', 'karma-phantomjs-launcher', 'karma-chrome-launcher', 'karma-firefox-launcher', 'karma-coverage', 'karma-spec-reporter'], browsers: ['PhantomJS', 'Firefox', 'Chrome'], reporters: ['spec', 'coverage'], coverageReporter: { dir: 'coverage', reporters: [{ type: 'json', subdir: '.', file: 'coverage.json', }, { type: 'lcov', subdir: '.' }, { type: 'text-summary' }] } }); }; |
这些配置都是什么意思呢?这里挨个说明一下:
frameworks: 使用的测试框架,这里依旧是我们熟悉又亲切的Mocha
files:测试页面需要加载的资源,上面的test目录下已经没有test.html了,所有需要加载内容都在这里指定,如果是CDN上的资源,直接写URL也可以,不过建议尽可能使用本地资源,这样测试更快而且即使没网也可以测试。这个例子里,第一行载入的是断言库Should.js,第二行是src下的所有代码,第三行载入测试代码
preprocessors:配置预处理器,在上面files载入对应的文件前,如果在这里配置了预处理器,会先对文件做处理,然后载入处理结果。这个例子里,需要对src目录下的所有资源添加覆盖率打点(这一步之前是通过gulp-istanbul来做,现在karma-coverage框架可以很方便的处理,也不需要钩子啥的了)。后面做React组件测试时也会在这里使用webpack
plugins:安装的插件列表
browsers:需要测试的浏览器,这里我们选择了PhantomJS、FireFox、Chrome
reporters:需要生成哪些代码报告
coverageReporter:覆盖率报告要如何生成,这里我们期望生成和之前一样的报告,包括覆盖率页面、lcov.info、coverage.json、以及命令行里的提示
好了,配置完成,来试试吧,运行./node_modules/karma/bin/karma start --single-run,可以看到如下输出:
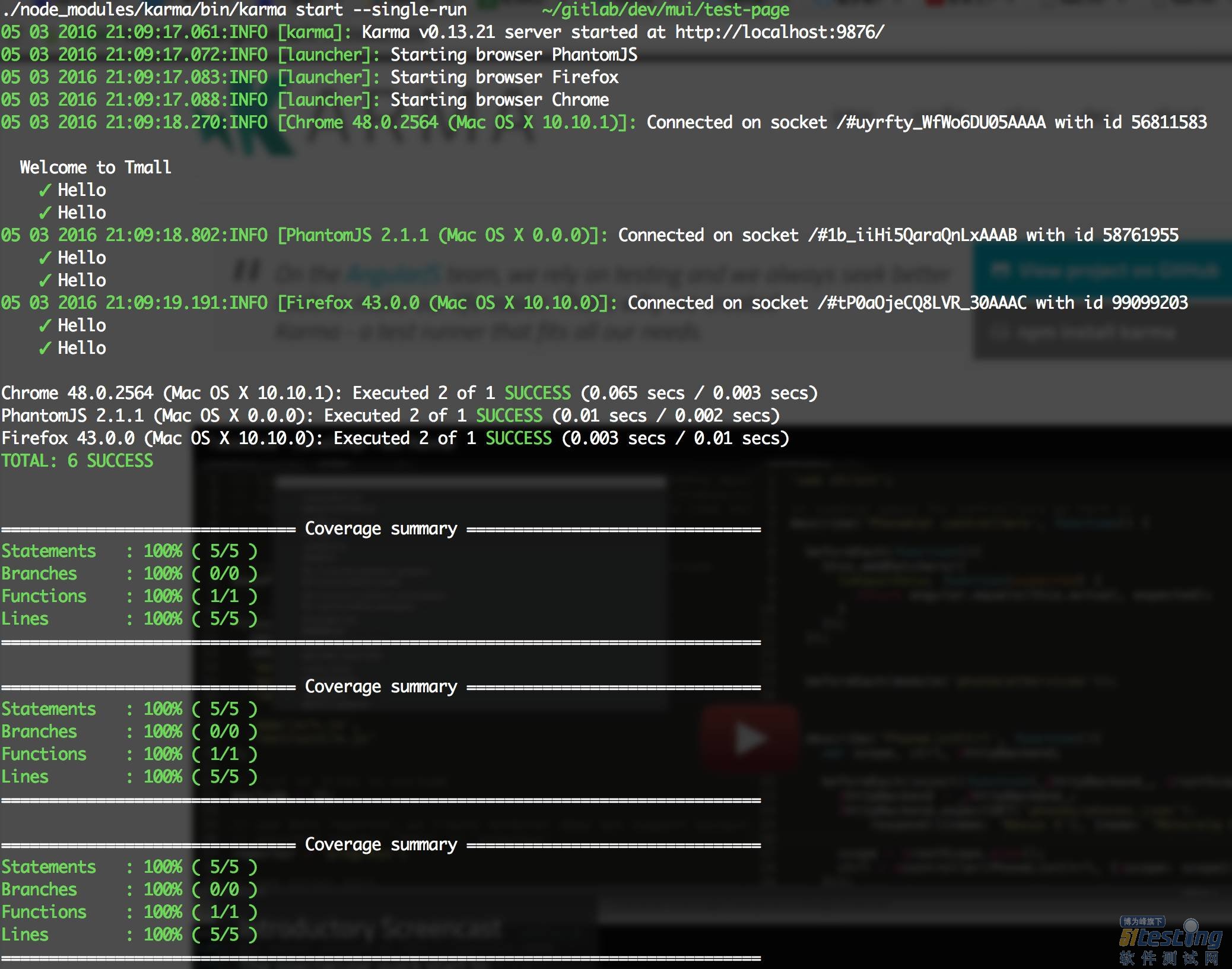
可以看到,Karma首先会在9876端口开启一个本地服务,然后分别启动PhantomJS、FireFox、Chrome去加载这个页面,收集到测试结果信息之后分别输出,这样跨浏览器测试就解决啦。如果要新增浏览器就安装对应的浏览器插件,然后在browsers里指定一下即可,非常灵活方便。
那如果我的mac电脑上没有IE,又想测IE,怎么办呢?可以直接运行./node_modules/karma/bin/karma start启动本地服务器,然后使用其他机器开对应浏览器直接访问本机的9876端口(当然这个端口是可配置的)即可,同样移动端的测试也可以采用这个方法。这个方案兼顾了前两个方案的优点,弥补了其不足,是目前看到最优秀的前端代码测试方案了












