

ЎЎЎЎТвНвѕЄПІ
ЎЎЎЎУРИэјюКВКЗОТГЗХвТ»№эіМГ»УРФ¤БПµЅµДЈ¬ЛьГЗґшёшОТГЗТ»Р©ТвНвѕЄПІЎЈ

ЎЎЎЎКЧПИКЗЈ¬ЛщУРїН»§ЙП±ЁµДИ±ПЭЦРЈ¬УР38%ЧоЦХ»Ш№йБЛЎЈХвТвО¶ЧЕ±ѕАґТ»ёц№¦ДЬїЙТФХэіЈ№¤ЧчЈ¬ОТГЗРЮёДБЛІї·ЦґъВлЈЁОЄБЛРЮёґОКМв»тФцјУ№¦ДЬЈ©Ј¬ЛжєуУГ»§ЙП±ЁіЖФ±ѕХэіЈµД№¦ДЬОЮ·ЁК№УГБЛЎЈОТГЗІўОґФЪДЪІї·ўПЦХвСщµДОКМвЎЈµ«ОТГЗЦЄµАЈ¬ЧФјєТІЅшРРБЛ»Ш№йІвКФЈ¬їЙЅбВЫЦРµДКэѕЭІўГ»УРДЗГґёЯЎЈХвТвО¶ЧЕОТГЗІўІ»ѕЯ±ёИОєОАаРНµДЧФ¶Ї»ЇІвКФїЙТФідµ±јмІв»ъЦЖЈ¬ІўёжЛЯОТГЗЎ°ДгёХёХФцјУµДДЗ¶ОґъВлїЙТФХэіЈ№¤ЧчЈ¬µ«»бЖЖ»µДіёцФУР№¦ДЬЈ¬·ўІјЗ°Т»¶ЁТЄјмІйІўРЮёґЎ±ЎЈНЁ№э±аРґЧФ¶Ї»ЇІвКФЈ¬јґїЙЅ«О»УЪБЅёцІ»Н¬О»ЦГµД№¦ДЬВЯјЎ°ХієПЎ±ФЪТ»ЖрЎЈµ«ХвКЗТ»±ъЛ«ИРЅЈЎЈїЙТФ°пЦъОТГЗёьёЯР§µШІ¶ЧЅ»Ш№йЈ¬µ«Н¬К±ТІїЙДЬНПАЫЗ°ЅшµДЅЕІЅЎЈМбЅ»Ц®єуіцПЦМ«¶аК§°ЬµДІвКФ»бЅµµНОТГЗµДЛЩ¶ИЈ¬ТтОЄФЪјМРшЦ®З°»№РиТЄРЮёґХвР©ОКМвЎЈХвТ»№эіМРиТЄИЁєвЈ¬µ«¶ФОТГЗ¶шСФЈ¬ЦУ°ЪТСѕ°Ъ¶ЇµЅѕаАлОТГЗПЈНыКµПЦµДїмЛЩїЄ·ўМ«Ф¶µДёЯ¶ИЈ¬ТтґЛОТГЗРиТЄЕ¤ЧЄЧФјєµД·ЅПтЎЈ
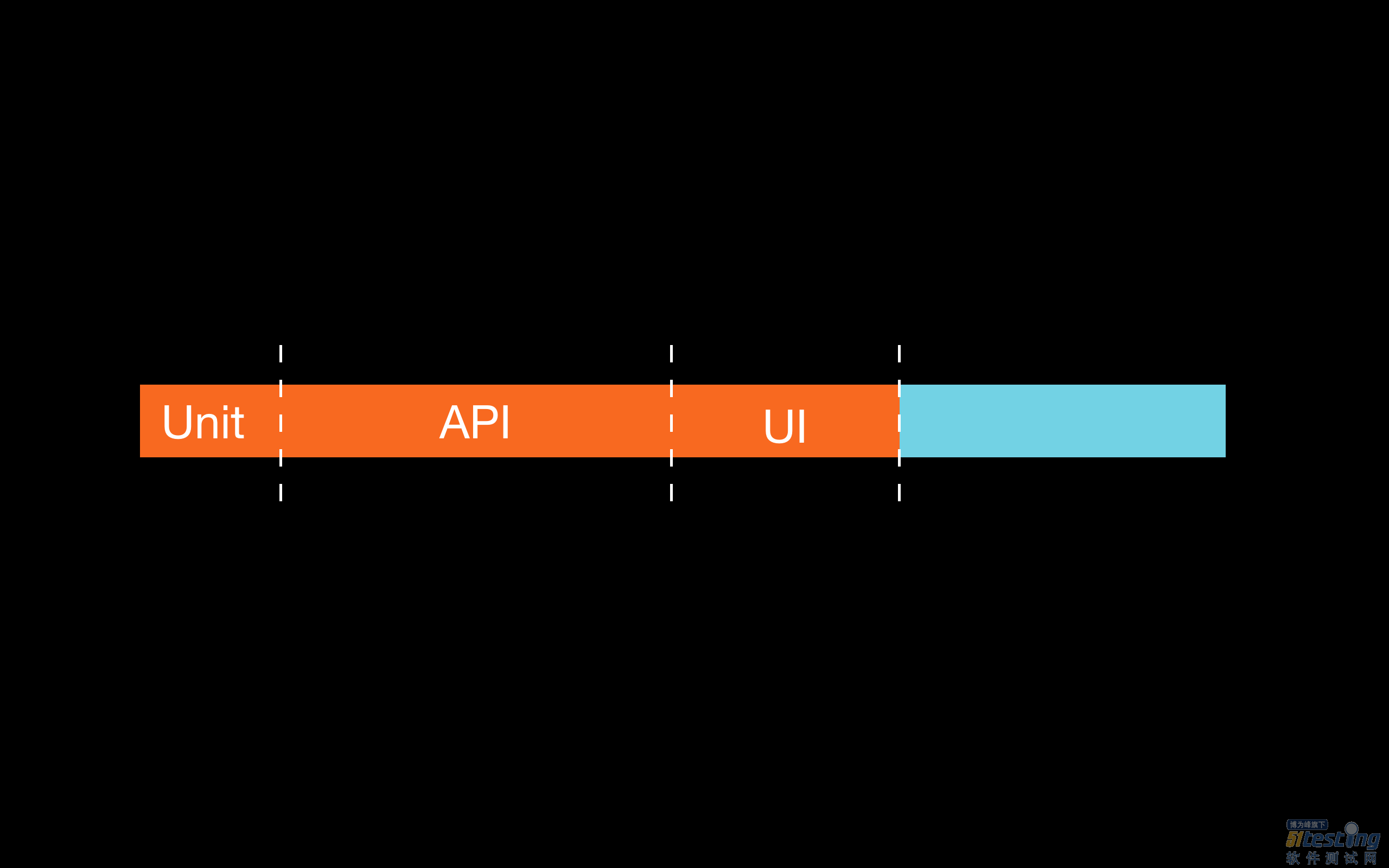
ЎЎЎЎµЪ¶юёцѕЄПІКЗЈє ЧФ¶Ї»ЇІвКФЅрЧЦЛюЦёДП ІўІ»ДЬ°пЦъОТГЗМбФз·ўПЦёь¶аИ±ПЭЎЈїН»§ЙП±ЁµДИ±ПЭЦРЈ¬ЅцУР13%їЙТФНЁ№э±аРґµҐФЄІвКФМбФз·ўПЦЈ¬¶шУлЦ®¶ФУ¦µДЈ¬APIІгГжµДІвКФїЙМбФз·ўПЦЖдЦРµД36%Ј¬UIІгГжµДІвКФїЙ·ўПЦ21%ЎЈБвРОЈЁґуІї·ЦІвКФ¶јФЪAPIІгГжЙПЅшРРЈ©±ИЅрЧЦЛюРОёьККєПОТГЗЎЈХвТ»ОКМвФґЧФОТГЗИнјюµД±ѕЦКМШХчЎЈОТГЗµДИнјюКЗSaaSУ¦УГЈ¬ЦчТЄ№¦ДЬКЗНЁ№э»ҐБЄНшКХјЇґуБїКэѕЭЈ¬ІўЅ«Жд±ЈґжФЪІ»Н¬КэѕЭївЦРТФ№©єуРш·ЦОцЎЈґуІї·ЦИ±ПЭО»УЪІ»Н¬ИнјюµДЎ°·мП¶Ў±ЦРЎЈОТГЗУРі¬№э19ЦЦІ»Н¬·юОсЈ¬ХвР©·юОсѕщРиТЄІ»¶ПЅшРРНшВзНЁРЕЎЈХвР©·юОсµДґъВлО»УЪІ»Н¬ґъВлївЦРЈ¬ТтґЛЅцК№УГµҐФЄІвКФОЮ·Ё»сµГЧг№»єГµДР§№ыЈЁОТГЗїјВЗЦ»ФЪДЪґжЦРФЛРРµҐФЄІвКФЈ¬І»Йжј°НшВзєНКэѕЭївОДјюПµНіЈ¬Из№ыУР±ШТЄ»№»бЅ«ІвКФКэБї·±¶Ј©ЎЈН¬К±ОТГЗИПОЄЈ¬ЛжЧЕОў·юОсєНLambdaєЇКэµДбИЖрЈ¬Па±ИјтµҐµДµҐФЄІвКФЈ¬Хл¶ФНкХыІїКрµДУ¦УГЅшРРёЯІгГжµДјЇіЙКЅІвКФїЙТФёьУРР§µШ·ўПЦИ±ПЭЎЈґуІї·ЦИ±ПЭО»УЪІ»Н¬·юОсµШ±ЯЅзЦ®јдЈ¬Ц»УРХл¶ФНкХыІїКрµДУ¦УГіМРтЅшРРІвКФІЕДЬ·ўПЦЎЈФЪёфАлµД»·ѕіЦРЈЁК№УГµҐФЄІвКФЈ©¶ФґъВлЖ¬¶ОЅшРРІвКФЈ¬КЗОЮ·Ё·ўПЦХвР©И±ПЭµДЎЈ

ЎЎЎЎµҐФЄІвКФТАИ»єЬУРУГЈ¬µ«ІўІ»РиТЄ¶ФЛщУРґъВлЦґРРґЛАаІвКФЎЈОТГЗ·ўПЦЦ»¶ФС»·ёґФУ¶ИЈЁCyclomatic complexityЈ©І»µНУЪ3µД·Ѕ·ЁЈЁ72%µДИ±ПЭО»УЪґЛАа·Ѕ·ЁЦРЈ©ТФј°№жДЈі¬№э10РРґъВлµД·Ѕ·ЁЈЁ82%µДИ±ПЭО»УЪґЛАа·Ѕ·ЁЦРЈ©ЅшРРµҐФЄІвКФѕН№»БЛЎЈ

ЎЎЎЎµЪИэёцѕЄПІКЗЈєОЮВЫФЪДЪІїЅшРРєОЦЦАаРНµДІвКФЈ¬¶јОЮ·ЁНкИ«·ўПЦЛщУРИ±ПЭЎЈКјЦХУР30%µДИ±ПЭЦ»ДЬУЙїН»§·ўПЦЎЈОЄКІГґЈї±ЯФµ°ёАэЎўЙъІъ»·ѕіµДЕдЦГОКМвЎў·ЗФ¤ЖЪК№УГДЈКЅЎўІ»НкХы»тґнОуµД№ж·¶ЎЈИз№ыУРЧг№»µДК±јдЎўЧКЅрєНЧКФґЈ¬ОТГЗТІїЙТФ·ўПЦДЗ30%µДИ±ПЭЈ¬µ«¶ФОТГЗАґЛµХвСщЧцФЪѕјГЙПІ»їЙРРЎЈОТГЗГжБЩј¤БТµДКРіЎѕєХщЈ¬РиТЄїмЛЩЗ°ЅшЎЈУлЖдУАФ¶µИґэЧЕ·ўПЦДЗЖ®ГмµД30%Ј¬І»ИзИОЖдґжФЪЈ¬µ« ОТГЗ»бѕЎїЙДЬНЁ№эУЕ»ЇМбЗ°·ўПЦЛьГЗІўїмЛЩРЮёґ ЎЈµ±їН»§ЙП±ЁБЛґЛАаИ±ПЭІўНкіЙµчІйЈ¬ОТГЗ»бґУЦРС§П°ѕСйІўЅшТ»ІЅНкЙЖОТГЗµДПµНіЎЈ
ЎЎЎЎѕЩґл
ЎЎЎЎОТГЗХл¶ФїЄ·ўХЯєНІвКФИЛФ±µДБчіМЅшРРБЛЛДёцёД¶ЇЈє
ЎЎЎЎГїёц№¦ДЬЦБЙЩРґТ»ёцЧФ¶Ї»ЇІвКФЎЈИз№ыїЙДЬЈ¬ѕЎБїЧЁЧўУЪAPIІвКФЈ¬ТтОЄХвСщУРЦъУЪХТіцёь¶аИ±ПЭЎЈ
ЎЎЎЎѕНЛгЧоРЎ№жДЈµДРЮёґЈ¬ТІТЄКЦ№¤ЅшРРЅЎИ«РФјмІйєНЦ±№ЫСйЦ¤ЎЈ
ЎЎЎЎТЄЗуНЕ¶УБмµјЅшРРґъВлЙуІйЎЈіэ·ЗЙуІйНЁ№эЈ¬·сФтґъВлІ»ФКРнНЖЛНЦБЙъІъ»·ѕіЎЈ
ЎЎЎЎІвКФ№эіМѕЎїЙДЬК№УГ±ЯЅзЦµЈє№э¶аКэѕЭЎў№эЙЩКэѕЭЎўДкіхєНДкµЧµИЈ¬8%µДИ±ПЭ¶јКЗґЛАаЦµТэЖрµДЎЈ
ЎЎЎЎґЛНвФЪјјКх·ЅГжТІУРЛДёцёД¶ЇЈє
ЎЎЎЎ1) ГїМмФзіїЙуІйЙъІъ»·ѕі№эИҐ24РЎК±µДИХЦѕЈ¬ФЪЖдЦРІйХТґнОуєНТміЈЎЈИз№ы·ўПЦОКМвЈ¬ФтТФёЯУЕПИј¶РЮёґЎЈХвСщѕНїЙТФѕЎїЙДЬФз·ўПЦОКМвЈ¬УРК±їН»§ґтµз»°ёжЦЄОТГЗУцµЅОКМвЈ¬ОТГЗТСѕїЄКјЧЕКЦРЮёґБЛЎЈ

ЎЎЎЎ2) ОТГЗУРі¤К±јдФЛРРµДAPIјЇіЙІвКФЈ¬ТФЗ°НЁіЈРиТЄФЛРРИэРЎК±ЎЈНЁ№э±ШТЄµДёДЅшЈЁЦчТЄёДЅшОЄЈєЧЁУГІвКФ»·ѕіЎўІвКФКэѕЭЙъіЙЎўДЈДвНвІї·юОсЎўІўРРФЛРРЈ©Ј¬ПаН¬ІвКФПЦФЪїЙФЪИэ·ЦЦУДЪНкіЙЎЈОТГЗФшКЬСыФЪ2016ДкGoogle Test Automation ConferenceЙПЅйЙЬБЛЧФјєµДЧц·ЁЈє їКНыЛЩ¶И ЁC Ѕ«ЧФ¶Ї»ЇІвКФґУ3РЎК±МбЛЩЦБ3·ЦЦУ ЎЈХвИГОТГЗµДИ±ПЭІйХТ№эіМКµПЦБЛ·ЙФѕЈ¬ТтОЄїЙТФФЪГїґОМбЅ»єуЧФ¶ЇФЛРРЛщУРІвКФЈЁѕІМ¬ґъВл·ЦОцЎўµҐФЄІвКФЎўAPIІвКФЈ©ЎЈПЦФЪОТГЗТСѕІ»РиТЄГїНнЅшРРІвКФЈ¬ТІІ»ФЩРиТЄГ°СМІвКФЈЁSmoke testЈ©ЎЈИз№ыЛщУРјмІйѕщіЙ№¦НЁ№эЈ¬ѕНїЙТФ·ЗіЈЧФРЕµШБўјґ·ўІјµЅЙъІъ»·ѕіЎЈ
ЎЎЎЎ3) ЙъІъ»·ѕіЦРµДИ±ПЭУРК±єт»бФміЙТміЈЈ¬¶шХвР©ТміЈ»бФЪУ¦УГіМРтµДИХЦѕОДјюЦРБфПВПЯЛчЎЈµчІй№эіМЦРЈ¬ОТГЗ·ўПЦПаН¬µДТміЈЙхЦБФзФЪ·ўІјµЅЙъІъ»·ѕіЦ®З°Ј¬ѕНТСѕіцПЦФЪІвКФ»·ѕіµДИХЦѕОДјюЦРБЛЎЈХвСщАґїґЈ¬ЖдКµОТГЗФЪХжХэ·ўІјµЅЙъІъ»·ѕіЗ°Ј¬ѕНУР»ъ»б·ўПЦХвР©И±ПЭЈ¬µ«З°МбКЗ¶ФІвКФ»·ѕіµДИХЦѕЅшРРјаКУЎЈТтґЛОТГЗ¶ФЧФ¶Ї»ЇІвКФµДЦґРРЅшРРБЛТ»Р©ёД¶ЇЈ¬ѕНЛгЛщУРЧФ¶Ї»ЇAPIІвКФѕщТСіЙ№¦НЁ№эЈ¬ОТГЗТАИ»»бФЪГїґОІвКФНкіЙєујмІйИХЦѕОДјюЦРКЗ·сґжФЪґнОуєНТміЈЎЈУРК±єтТтОЄФгёвµД±аВлКµјщЈЁАэИзЦ»КЗјЗВјТміЈРЕПўµ«І»ЅшТ»ІЅА©ґуЈ©Ј¬іЙ№¦НЁ№эµДІвКФТІУРїЙДЬµјЦВДЪІїТміЈµ«ОЮ·ЁЦч¶ЇМеПЦіцАґЈЁАэИзЦч¶ЇИГІвКФК§°ЬЈ©ЎЈґЛК±ОТГЗ»бИГ№№ЅЁК§°ЬІўµчІйУцµЅµДТміЈЎЈ
ЎЎЎЎ4) ФјУР10%µДИ±ПЭКЗУЙОґДЬНЧЙЖґ¦АнµД·ЗФ¤ЖЪКэѕЭФміЙµДЈєМШКвЧЦ·ы»тUnicodeЧЦ·ыЎў¶юЅшЦЖКэѕЭЎўіцґнµДѕµПсЎЈОТГЗїЄКјКХјЇґЛАаКэѕЭЈ¬ІўФЪЧФ¶Ї»ЇІвКФРиТЄґґЅЁІвКФКэѕЭК±Ј¬»бК№УГХвР©ДЪИЭЧчОЄЎ°ТміЈЎ±КэѕЭЎЈ
ЎЎЎЎКХР§
ЎЎЎЎПВНјХ№КѕБЛОТГЗЛщУРѕЩґлµДКХР§Ј¬ГїёцЦщЧґМх¶ФУ¦Т»ёцјѕ¶ИЎЈЗлБфТвЧоєуЛДёцјѕ¶ИЈ¬їН»§ЙП±ЁµДИ±ПЭКэБїіЦРшПВЅµЎЈЙПёцјѕ¶ИОТГЗµДИ±ПЭКэБїКЗЧФґУБЅДк°лЗ°їЄКјКХјЇґЛАаРЕПўТФАґЧоЙЩµДЎЈЧоєуТ»ёцјѕ¶ИєНИ±ПЭКэБїЧо¶ајѕ¶ИЦ®јдµДЅµ·щі¬№эБЛЛД±¶ЎЈ
ЎЎЎЎБнНв»№УРТ»јюКВРиТЄЧўТвЎЈНЁіЈЈ¬ІъЖ·µДґъВлРРКэЈЁLoCЈ©ФЅґуЈ¬°ьє¬µДИ±ПЭѕНФЅ¶аЈ¬µ«И±ПЭКэБїєНґъВлРРКэЦ®јдµД±ИАэКЗ№М¶ЁІ»±дµДЎЈФЪОТГЗµДЗйїцЦРЈ¬ЛдИ»ґъВлРРКэІ»¶ПФцјУЈ¬µ«ЧоєуЛДёцјѕ¶ИµДИ±ПЭКэБїФЪІ»¶ПЅµµНЎЈ
ЎЎЎЎИзєОЧЕКЦ
ЎЎЎЎµчІйїН»§ЙП±ЁИ±ПЭЈ¬И·¶ЁОКМвёщФґЈ¬НЁ№эРЮёґЅвѕцОКМвЈ¬КХјЇПа№ШРЕПўЈ¬Хыёц№эіМ¶ФґуІї·ЦИЛ¶шСФ¶јј«ОЄИЯ·іЎЈОТµДЅЁТйКЗЈєОЄИ±ПЭµчІйФ¤БфЧЁГЕµДК±јдЈЁАэИзГїМмТ»РЎК±Ј©ЎЈТ»µ©їЛ·юБЛЧоіхµДІ»ККУ¦Ц®єуЈ¬јЩЙиДгґтЛгµчІй№эИҐДіМм·ўПЦµДИ±ПЭЈ¬КэѕЭµДКХјЇ№эіМЅ«ёьјУНкЙЖЈ¬ЧФ¶Ї»ЇіМ¶ИТІ»бёьёЯЎЈИ»¶шѕЎ№ЬИзґЛЈ¬ОТµДѕ«Б¦ТАИ»І»ЧгТФЦ§іЕГїМм°ЛРЎК±µДИ±ПЭµчІйЎЈ
ЎЎЎЎИ·±ЈїЙТФЅ«їН»§ЙП±ЁµДИ±ПЭУлДЪІї·ўПЦµДИ±ПЭЗш·Ц¶ФґэЎЈФЪїЄ·ўРЮёґіМРтК±Ј¬ЗлЅ«И±ПЭµДID·ЕФЪМбЅ»РЕПўЦРЈ¬ХвСщјґїЙТ»Т»¶ФУ¦ЎЈ
ЎЎЎЎѕЎїЙДЬј°К±µШµчІйИ±ПЭ ЎЄ µИµДФЅѕГЈ¬РиТЄ»Ё·СµДК±јдѕНФЅ¶аЈ¬±Пѕ№ИЛµДјЗТдєЬїм»бЛҐНЛЎЈ
ЎЎЎЎИГНЕ¶УЦ®НвµДДіИЛёєФрµчІйИ±ПЭЎЈХвёцИЛІ»У¦УлґъВлУРИОєОёРЗйБЄПµЈ¬·сФтєЬУРїЙДЬЧціцІ»№»їН№ЫµДЕР¶ПЎЈ
ЎЎЎЎИз№ыТЄЧ·ЧЩМ«¶аЦё±кЈ¬ДгєЬїм»б±»СНГ»ЖдЦРЈ¬ТтґЛРиТЄГчИ·ДДР©Цё±к¶ФЧйЦЇ¶шСФКЗУРУГµДЈ¬КЗїЙРРµДЎЈ
ЎЎЎЎКХјЇЛщУРґЛАаРЕПўЛЖєхРиТЄґуБї№¤ЧчЈЁИ·КµИзґЛЈ©Ј¬µ«ОТёТ±ЈЦ¤ДгµДГїГлЦУН¶Ил¶јКЗЦµµГµДЎЈХвТ»№эіМ»№ОЄДгМṩБЛѕЮґуµДС§П°»ъ»бЎЈ
ЎЎЎЎЅбВЫ
ЎЎЎЎµчІйїН»§ЙП±ЁИ±ПЭµДёщФґДЬОЄЧйЦЇґшАґѕЮґујЫЦµЎЈЧоїЄКјµДКэѕЭКХјЇ№¤ЧчєЬІ»ИЭТЧЈ¬µ«ЖдЦРФМє¬БЛґуБїС§П°µД»ъ»бЎЈИГИЛіФѕЄµДКЗУкܶ๫˾ĿǰІўГ»УРХвСщЧцЎЈДїЗ°µДґуІї·ЦЧйЦЇ¶јФЪХщ¶бН¬Т»ЕъИЛІЕЈ¬»тХЯїЙТФК№УГПаН¬µДУІјюЧКФґЈЁAWSЈ©Ј¬ДгУЦёГИзєОНСУ±¶шіцЈїОЄБЛО¬іЦїН»§ВъТв¶ИЈ¬ЅµµНіЙ±ѕЈ¬МбёЯФ±№¤ІОУл»эј«РФЈ¬ЧојСµД°м·ЁКЗЎ°ДЪКУЎ±Ј¬±Пѕ№ДгТСѕУРКэѕЭБЛЎЈЧоЦХЈ¬ЛщУРѕЩґл¶јКЗОЄБЛКµПЦіЦРшІ»¶ПµДёДЅшЎЈ












