

NoSQL 这个词在近些年正变得随处可见. 但是到底 "NoSQL" 指的是什么? 它是如何并且为什么这么有用? 在本文, 我们将会通过纯 Python (我比较喜欢叫它, "轻结构化的伪代码") 写一个 NoSQL 数据库来回答这些问题.
OldSQL
很多情况下, SQL 已经成为 "数据库" (database) 的一个同义词. 实际上, SQL 是 Strctured Query Language 的首字母缩写, 而并非指数据库技术本身. 更确切地说, 它所指的是从 RDBMS (关系型数据库管理系统, Relational Database Management System ) 中检索数据的一门语言. MySQL, MS SQL Server 和 Oracle 都属于 RDBMS 的其中一员.
RDBMS 中的 R, 即 "Relational" (有关系,关联的), 是其中内容最丰富的部分. 数据通过 表 (table) 进行组织, 每张表都是一些由 类型 (type) 相关联的 列 (column) 构成. 所有表, 列及其类的类型被称为数据库的 schema (架构或模式). schema 通过每张表的描述信息完整刻画了数据库的结构. 比如, 一张叫做 Car 的表可能有以下一些列:
· Make: a string
· Model: a string
· Year: a four-digit number; alternatively, a date
· Color: a string
· VIN(Vehicle Identification Number): a string
在一张表中, 每个单一的条目叫做一 行 (row), 或者一条 记录 (record). 为了区分每条记录, 通常会定义一个 主键 (primary key). 表中的 主键 是其中一列 , 它能够唯一标识每一行. 在表 Car 中, VIN 是一个天然的主键选择, 因为它能够保证每辆车具有唯一的标识. 两个不同的行可能会在 Make, Model, Year 和 Color 列上有相同的值, 但是对于不同的车而言, 肯定会有不同的 VIN. 反之, 只要两行拥有同一个 VIN, 我们不必去检查其他列就可以认为这两行指的的就是同一辆车.
Querying
SQL 能够让我们通过对数据库进行 query (查询) 来获取有用的信息. 查询 简单来说, 查询就是用一个结构化语言向 RDBMS 提问, 并将其返回的行解释为问题的答案. 假设数据库表示了美国所有的注册车辆, 为了获取 所有的 记录, 我们可以通过在数据库上进行如下的 SQL 查询 :
SELECT Make, Model FROM Car;
将 SQL 大致翻译成中文:
· "SELECT": "向我展示"
· "Make, Model": "Make 和 Model 的值"
· "FROM Car": "对表 Car 中的每一行"
也就是, "向我展示表 Car 每一行中 Make 和 Model 的值". 执行查询后, 我们将会得到一些查询的结果, 其中每个都是 Make 和 Model. 如果我们仅关心在 1994 年注册的车的颜色, 那么可以:
SELECT Color FROM Car WHERE Year = 1994;
此时, 我们会得到一个类似如下的列表:
Black
Red
Red
White
Blue
Black
White
Yellow
最后, 我们可以通过使用表的 (primary key) 主键 , 这里就是 VIN 来指定查询一辆车:
SELECT * FROM Car WHERE VIN = '2134AFGER245267'
上面这条查询语句会返回所指定车辆的属性信息.
主键被定义为唯一不可重复的. 也就是说, 带有某一指定 VIN 的车辆在表中至多只能出现一次. 这一点非常重要,为什么? 来看一个例子:
Relations
假设我们正在经营一个汽车修理的业务. 除了其他一些必要的事情, 我们还需要追踪一辆车的服务历史, 即在该辆车上所有的修整记录. 那么我们可能会创建包含以下一些列的 ServiceHistory 表:
VIN | Make | Model | Year | Color | Service Performed | Mechanic | Price | Date
这样, 每次当车辆维修以后, 我们就在表中添加新的一行, 并写入该次服务我们做了一些什么事情, 是哪位维修工, 花费多少和服务时间等.
但是等一下, 我们都知道,对于同一辆车而言,所有车辆自身信息有关的列是不变的。 也就是说,如果把我的 Black 2014 Lexus RX 350 修整 10 次的话, 那么即使 Make, Model, Year 和 Color 这些信息并不会改变,每一次仍然重复记录了这些信息. 与无效的重复记录相比, 一个更合理的做法是对此类信息只存储一次, 并在有需要的时候进行查询。
那么该怎么做呢? 我们可以创建第二张表: Vehicle , 它有如下一些列:
VIN | Make | Model | Year | Color
这样一来, 对于 ServiceHistory 表, 我们可以精简为如下一些列:
VIN | Service Performed | Mechanic | Price | Date
你可能会问,为什么 VIN 会在两张表中同时出现? 因为我们需要有一个方式来确认在 ServiceHistory 表的 这 辆车指的就是 Vehicle 表中的 那 辆车, 也就是需要确认两张表中的两条记录所表示的是同一辆车。 这样的话,我们仅需要为每辆车的自身信息存储一次即可. 每次当车辆过来维修的时候, 我们就在 ServiceHistory 表中创建新的一行, 而不必在 Vehicle 表中添加新的记录。 毕竟, 它们指的是同一辆车。
我们可以通过 SQL 查询语句来展开 Vehicle 与 ServiceHistory 两张表中包含的隐式关系:
SELECT Vehicle.Model, Vehicle.Year FROM Vehicle, ServiceHistory WHERE Vehicle.VIN = ServiceHistory.VIN AND ServiceHistory.Price > 75.00;
该查询旨在查找维修费用大于 $75.00 的所有车辆的 Model 和 Year. 注意到我们是通过匹配 Vehicle 与 ServiceHistory 表中的 VIN 值来筛选满足条件的记录. 返回的将是两张表中符合条件的一些记录, 而 "Vehicle.Model" 与 "Vehicle.Year" , 表示我们只想要 Vehicle 表中的这两列.
如果我们的数据库没有 索引 (indexes) (正确的应该是 indices), 上面的查询就需要执行 表扫描 (table scan) 来定位匹配查询要求的行。 table scan 是按照顺序对表中的每一行进行依次检查, 而这通常会非常的慢。 实际上, table scan 实际上是所有查询中最慢的。
可以通过对列加索引来避免扫描表。 我们可以把索引看做一种数据结构, 它能够通过预排序让我们在被索引的列上快速地找到一个指定的值 (或指定范围内的一些值). 也就是说, 如果我们在 Price 列上有一个索引, 那么就不需要一行一行地对整个表进行扫描来判断其价格是否大于 75.00, 而是只需要使用包含在索引中的信息 “跳” 到第一个价格高于 75.00 的那一行, 并返回随后的每一行(由于索引是有序的, 因此这些行的价格至少是 75.00)。
当应对大量的数据时, 索引是提高查询速度不可或缺的一个工具。当然, 跟所有的事情一样,有得必有失, 使用索引会导致一些额外的消耗: 索引的数据结构会消耗内存,而这些内存本可用于数据库中存储数据。这就需要我们权衡其利弊,寻求一个折中的办法, 但是为经常查询的列加索引是 非常 常见的做法。
The Clear Box
得益于数据库能够检查一张表的 schema (描述了每列包含了什么类型的数据), 像索引这样的高级特性才能够实现, 并且能够基于数据做出一个合理的决策。 也就是说, 对于一个数据库而言, 一张表其实是一个 “黑盒” (或者说透明的盒子) 的反义词?
当我们谈到 NoSQL 数据库的时候要牢牢记住这一点。 当涉及 query 不同类型数据库引擎的能力时, 这也是其中非常重要的一部分。
Schemas
我们已经知道, 一张表的 schema , 描述了列的名字及其所包含数据的类型。它还包括了其他一些信息, 比如哪些列可以为空, 哪些列不允许有重复值, 以及其他对表中列的所有限制信息。 在任意时刻一张表只能有一个 schema, 并且 表中的所有行必须遵守 schema 的规定 。
这是一个非常重要的约束条件。 假设你有一张数据库的表, 里面有数以百万计的消费者信息。 你的销售团队想要添加额外的一些信息 (比如, 用户的年龄), 以期提高他们邮件营销算法的准确度。 这就需要来 alter (更改) 现有的表 -- 添加新的一列。 我们还需要决定是否表中的每一行都要求该列必须有一个值。 通常情况下, 让一个列有值是十分有道理的, 但是这么做的话可能会需要一些我们无法轻易获得的信息(比如数据库中每个用户的年龄)。因此在这个层面上,也需要有些权衡之策。
此外,对一个大型数据库做一些改变通常并不是一件小事。为了以防出现错误,有一个回滚方案非常重要。但即使是如此,一旦当 schema 做出改变后,我们也并不总是能够撤销这些变动。 schema 的维护可能是 DBA 工作中最困难的部分之一。
Key/Value Stores
在 “NoSQL” 这个词存在前, 像 memcached 这样的 键/值 数据存储 (Key/Value Data Stores) 无须 table schema 也可提供数据存储的功能。 实际上, 在 K/V 存储时, 根本没有 "表 (table)" 的概念。 只有 键 (keys) 与 值 (values) . 如果键值存储听起来比较熟悉的话, 那可能是因为这个概念的构建原则与 Python 的 dict 与 set 相一致: 使用 hash table (哈希表) 来提供基于键的快速数据查询。 一个基于 Python 的最原始的 NoSQL 数据库, 简单来说就是一个大的字典 (dictionary) .
为了理解它的工作原理,亲自动手写一个吧! 首先来看一下一些简单的设计想法:
· 一个 Python 的 dict 作为主要的数据存储
· 仅支持 string 类型作为键 (key)
· 支持存储 integer, string 和 list
· 一个使用 ASCLL string 的简单 TCP/IP 服务器用来传递消息
· 一些像 INCREMENT, DELETE , APPEND 和 STATS 这样的高级命令 (command)
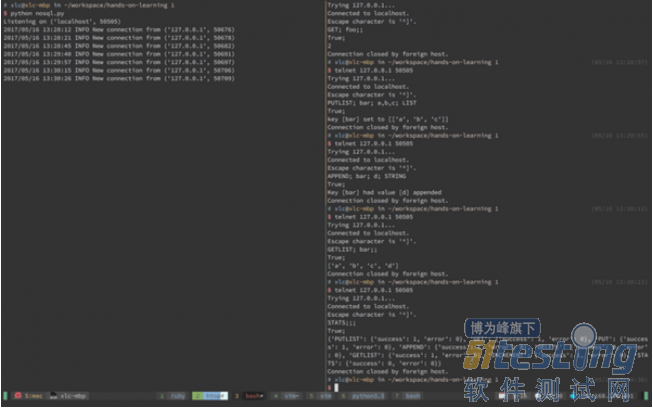
有一个基于 ASCII 的 TCP/IP 接口的数据存储有一个好处, 那就是我们使用简单的 telnet 程序即可与服务器进行交互, 并不需要特殊的客户端 (尽管这是一个非常好的练习并且只需要 15 行代码即可完成)。
对于我们发送到服务器及其它的返回信息,我们需要一个 “有线格式”。下面是一个简单的说明:
Commands Supported
PUT
参数: Key, Value
目的: 向数据库中插入一条新的条目 (entry)
GET
参数: Key
目的: 从数据库中检索一个已存储的值
PUTLIST
参数: Key, Value
目的: 向数据库中插入一个新的列表条目
APPEND
参数: Key, Value
目的: 向数据库中一个已有的列表添加一个新的元素
INCREMENT
参数: key
目的: 增长数据库的中一个整型值
DELETE
参数: Key
目的: 从数据库中删除一个条目
STATS
参数: 无 (N/A)
目的: 请求每个执行命令的 成功/失败 的统计信息
现在我们来定义消息的自身结构。
Message Structure
Request Messages
一条 请求消息 (Request Message) 包含了一个命令(command),一个键 (key), 一个值 (value), 一个值的类型(type). 后三个取决于消息类型,是可选项, 非必须。; 被用作是分隔符。即使并没有包含上述可选项, 但是在消息中仍然必须有三个 ; 字符。
COMMAND; [KEY]; [VALUE]; [VALUE TYPE]
· COMMAND 是上面列表中的命令之一
· KEY 是一个可以用作数据库 key 的 string (可选)
· VALUE 是数据库中的一个 integer, list 或 string (可选)
· list 可以被表示为一个用逗号分隔的一串 string, 比如说, "red, green, blue"
· VALUE TYPE 描述了 VALUE 应该被解释为什么类型
可能的类型值有:INT, STRING, LIST
· Examples
· "PUT; foo; 1; INT"
· "GET; foo;;"
· "PUTLIST; bar; a,b,c ; LIST"
· "APPEND; bar; d; STRING"
· "GETLIST; bar; ;"
· STATS; ;;
· INCREMENT; foo;;
· DELETE; foo;;
· Reponse Messages
一个 响应消息 (Reponse Message) 包含了两个部分, 通过 ; 进行分隔。第一个部分总是 True|False , 它取决于所执行的命令是否成功。 第二个部分是命令消息 (command message), 当出现错误时,便会显示错误信息。对于那些执行成功的命令,如果我们不想要默认的返回值(比如 PUT), 就会出现成功的信息。 如果我们返回成功命令的值 (比如 GET), 那么第二个部分就会是自身值。
Examples
· True; Key [foo] set to [1]
· True; 1
· True; Key [bar] set to [['a', 'b', 'c']]
· True; Key [bar] had value [d] appended
· True; ['a', 'b', 'c', 'd']
· True; {'PUTLIST': {'success': 1, 'error': 0}, 'STATS': {'success': 0, 'error': 0}, 'INCREMENT': {'success': 0, 'error': 0}, 'GET': {'success': 0, 'error': 0}, 'PUT': {'success': 0, 'error': 0}, 'GETLIST': {'success': 1, 'error': 0}, 'APPEND': {'success': 1, 'error': 0}, 'DELETE': {'success': 0, 'error': 0}}
Show Me The Code!
我将会以块状摘要的形式来展示全部代码。 整个代码不过 180 行,读起来也不会花费很长时间。












