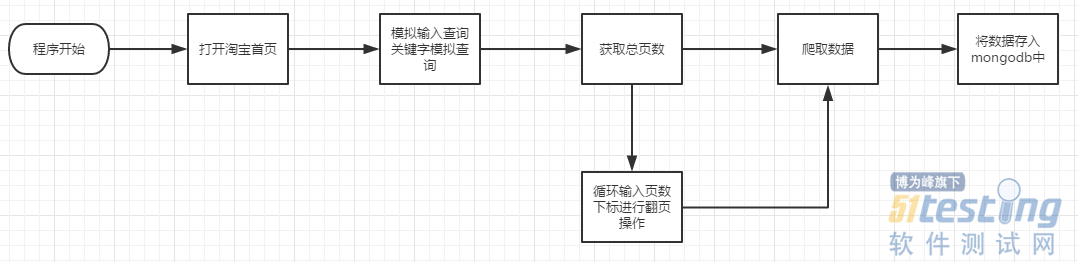
1、项目流程
2、中心调度
# 中心调度 def main(): try: total = search() total = int(re.compile('.*?(\d+).*?').search(total).group(1)) for i in range(2,total+1): next_page(i) except Exception as e: print('异常') finally: browser.close() |
3、模拟查询
# 根据关键字查询 def search(): try: browser.get('https://www.taobao.com/') # 直到搜索框加载出 input_search = wait.until(EC.presence_of_element_located((By.ID,'q'))) # 直到搜索按钮可以点击 submit_button = wait.until(EC.element_to_be_clickable((By.CLASS_NAME,'btn-search'))) input_search.send_keys(KEYWORDS) submit_button.click() total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'div.wraper div.total'))) get_products() return total.text except TimeoutException as e: print('响应超时') |
4、下一页的操作
# 下一页爬取 def next_page(index): try: input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager div.form > input'))) submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#mainsrp-pager div.form > span.btn.J_Submit'))) input.clear() input.send_keys(index) submit.click() wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'),str(index))) get_products() except NoSuchElementException as e: print('元素未加载') return next_page(index) |
5、商品信息的解析
# 获取一页上所有的商品 def get_products(): wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-itemlist .items .item"))) html = browser.page_source doc = PyQuery(html) items = doc('.m-itemlist .items .item').items() for item in items: product = { 'image':item.find('.pic-link .img').attr('data-src'), 'price':float(item.find('.price').text()[2:]), 'deal':item.find('.deal-cnt').text()[:-3], 'title':item.find('.title').text(), 'shop':item.find('.shop').text(), 'location':item.find('.location').text(), 'keywords':KEYWORDS } save_to_mongo(product=product) |
6、完整代码
#!/usr/bin/python # -*- coding: utf-8 -*- import pymongo import re from pyquery import PyQuery from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import TimeoutException,NoSuchElementException from setting import * client = pymongo.MongoClient(MONGO_HOST) db = client[MONGO_DB] browser = webdriver.Chrome() wait = WebDriverWait(browser,10) # 根据关键字查询 def search(): try: browser.get('https://www.taobao.com/') # 直到搜索框加载出 input_search = wait.until(EC.presence_of_element_located((By.ID,'q'))) # 直到搜索按钮可以点击 submit_button = wait.until(EC.element_to_be_clickable((By.CLASS_NAME,'btn-search'))) input_search.send_keys(KEYWORDS) submit_button.click() total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'div.wraper div.total'))) get_products() return total.text except TimeoutException as e: print('响应超时') # 下一页爬取 def next_page(index): try: input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager div.form > input'))) submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#mainsrp-pager div.form > span.btn.J_Submit'))) input.clear() input.send_keys(index) submit.click() wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'),str(index))) get_products() except NoSuchElementException as e: print('元素未加载') return next_page(index) # 获取一页上所有的商品 def get_products(): wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-itemlist .items .item"))) html = browser.page_source doc = PyQuery(html) items = doc('.m-itemlist .items .item').items() for item in items: product = { 'image':item.find('.pic-link .img').attr('data-src'), 'price':float(item.find('.price').text()[2:]), 'deal':item.find('.deal-cnt').text()[:-3], 'title':item.find('.title').text(), 'shop':item.find('.shop').text(), 'location':item.find('.location').text(), 'keywords':KEYWORDS } save_to_mongo(product=product) # 保存至mongoDB def save_to_mongo(product): try: if db[MONGO_TABLE].insert(product): print('保存成功', product) except Exception: print('保存失败') # 中心调度 def main(): try: total = search() total = int(re.compile('.*?(\d+).*?').search(total).group(1)) for i in range(2,total+1): next_page(i) except Exception as e: print('异常') finally: browser.close() if __name__=='__main__': main() |
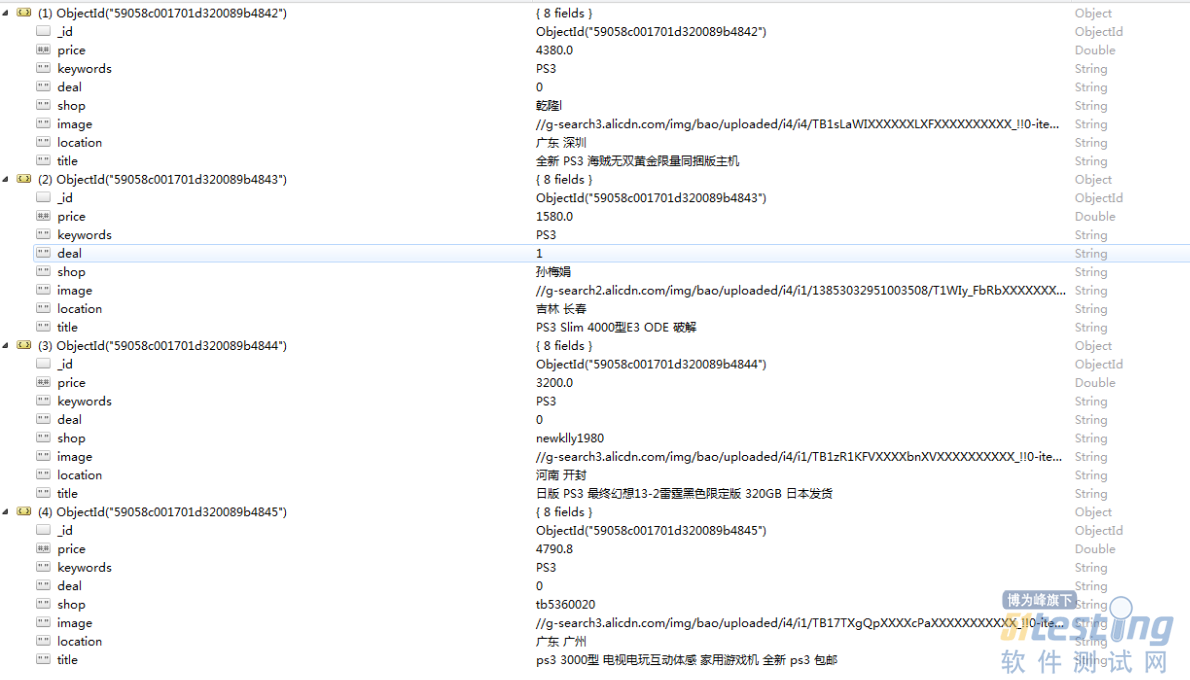
7、运行结果