

ЎЎЎЎ6.hdfs-site.xmlЕдЦГ
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>10.10.11.181:50090</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/root/hadoop/hdfs/namenode/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/root/hadoop/hdfs/datanode/dfs/data</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration> |
ЎЎЎЎ7.ЕдЦГmapred-site.xml
ЎЎЎЎПИёґЦЖФЩРЮёД
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>192.168.188.111:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>192.168.188.111:19888</value> </property> </configuration><span style="font-size:12px;"> </span> |
ЎЎЎЎ8.yarn-site.xmlЕдЦГ
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> </configuration> |
ЎЎЎЎ9.И»єу°СФЪmasterµДЕдЦГїЅ±ґµЅslave1єНslave2ЅЪµгЙП
ЎЎЎЎscp -r hadoop-2.7.3 root@192.168.188.112:/root/package
ЎЎЎЎИэЎўЖф¶Їhadoop
ЎЎЎЎ1.ёсКЅ»ЇГьБоЎЈТтОЄТСѕЕдЦГБЛhadoopµД»·ѕі±дБїЈ¬ЛщТФІ»Т»¶Ё·ЗТЄФЪhadoopµД°ІЧ°ДїВјКдИлёсКЅ»ЇГьБоЎЈ
ЎЎЎЎ[root@master sbin]# hdfs namenode -format
ЎЎЎЎ2.Жф¶Ї
ЎЎЎЎ[root@master sbin]# start-all.sh
ЎЎЎЎЛДЎўУГjpsІйїґЅб№ы
ЎЎЎЎЖф¶Їєу·Ц±рФЪmasterєНslave1єНslave2ПВІйїґЅшіМЎЈ
ЎЎЎЎmasterИзПВЈє

ЎЎЎЎslave1ИзПВЈє
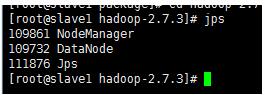
ЎЎЎЎslave2ИзПВЈє
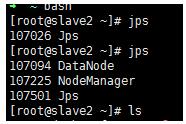
ЎЎЎЎФт±нКѕіЙ№¦ЎЈ
ЎЎЎЎОеЎўЅзГжІйїґСйЦ¤
ЎЎЎЎКдИлhttp://192.168.188.111:8088/
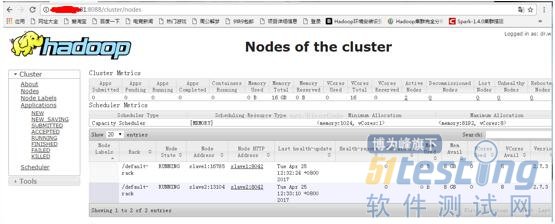
ЎЎЎЎКдИлhttp://192.168.188.111:50070/
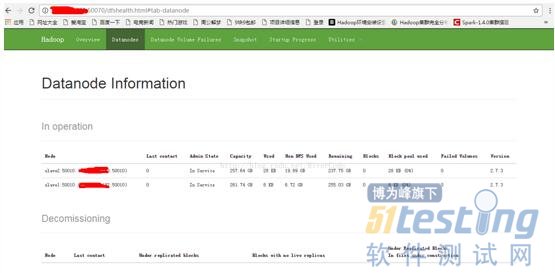
ЎЎЎЎµЅґЛЈ¬hadoop-2.7.3НкИ«·ЦІјКЅјЇИєґоЅЁіЙ№¦ЎЈ












