

ЎЎЎЎMaxCompute
ЎЎЎЎґуКэѕЭјЖЛг·юОс (MaxCompute) КЗТ»ЦЦїмЛЩЎўНкИ«НР№ЬµД PB/EB ј¶КэѕЭІЦїв·юОсЎЈѕЯ±ёНтМЁ·юОсЖчА©Х№ДЬБ¦єНїзµШУтИЭФЦДЬБ¦Ј¬КЗ°ўАп°Н°НДЪІїєЛРДґуКэѕЭјЖЛгЖЅМЁЈ¬Ц§іЕГїИХ°ЩНтј¶ЧчТµ№жДЈЎЈ
ЎЎЎЎMaxCompute КЗТ»ЦЦНіТ»µДґуКэѕЭјЖЛгЖЅМЁЈ¬ MaxCompute ПтУГ»§МṩБЛНкЙЖµДКэѕЭµјИл·Ѕ°ёТФј°¶аЦЦѕµдµД·ЦІјКЅјЖЛгДЈРНЈ¬±ИИз SQL ЎўНјјЖЛгЎўБчјЖЛгєН»ъЖчС§П°µИЈ¬ДЬ№»ёьїмЛЩµДЅвѕцУГ»§єЈБїКэѕЭјЖЛгОКМвЈ¬УРР§ЅµµНЖуТµіЙ±ѕЈ¬Іў±ЈХПКэѕЭ°ІИ«ЎЈ

ЎЎЎЎMaxCompute І»Ц»¶Ф°ўАпјЇНЕДЪІїУГ»§їЄ·ЕЈ¬ТІПтНвІїїЄ·ЕЎЈМмГЁЎўМФ±¦ЎўВмТПЅр·юµИ¶јФЪК№УГ MaxCompute Ј¬ MaxCompute КЗ°ўАпјЇНЕДЪІїЧо№ШјьµДґуКэѕЭЖЅМЁЈ¬ДїЗ°Ј¬ MaxCompute »ъЖчТСѕУРОеНт¶аМЁЈ¬КэѕЭ±нКЗ°ЩНтј¶ТФЙПЈ¬їЄ·ўХЯУР 8000 ¶аёцЈ¬РФДЬЙПКЗ hadoop2 ±¶µИЈ¬ґУКэѕЭЙПїЙТФёРКЬµЅ MaxCompute КЗГыё±ЖдКµµДєЈБїґуКэѕЭЖЅМЁЈ¬ФЪТµДЪДЬґ¦АнµДКэѕЭБїТФј°јЖЛгДЬБ¦ТІКЗґ¦УЪБмПИµШО»µДЎЈ
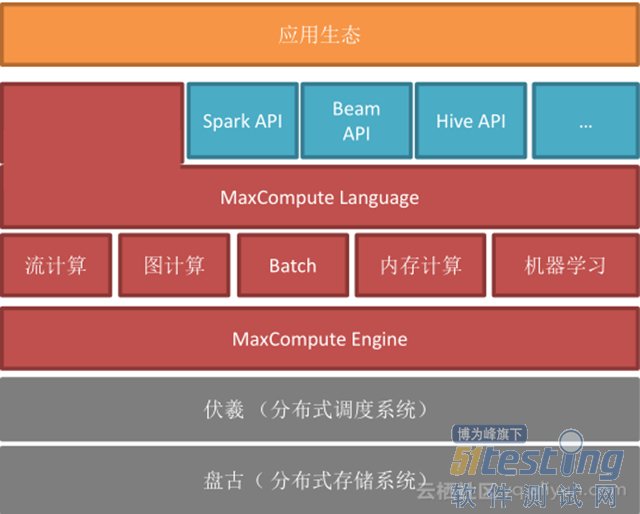
ЎЎЎЎMaxCompute µЧІгКЗУЙ°ўАпЧФЦчїЄ·ўµДЕМ№Е·ЦІјКЅґжґўПµНієН·ьфЛ·ЦІјКЅµч¶ИПµНіЧйіЙЈ¬ФЪґЛ»щґЎЙПЈ¬ОТГЗТІїЄ·ўБЛ MaxCompute ЦґРРТэЗжЈ¬ MaxCompute КЗНіТ»µДґуКэѕЭјЖЛгЖЅМЁЈ¬јИДЬЦ§іЦґ«НіѕµдµДЕъґ¦АнЈ¬ТІЦ§іЦБчјЖЛгЎўНјјЖЛгЎўДЪґжјЖЛгТФј°»ъЖчС§П°µИЈ¬ґУХвёцЅЗ¶ИАґїґЈ¬MaxCompute Ул spark ¶ЁО»·ЗіЈПаЛЖ;ФЪґЛЦ®ЙПЈ¬ MaxCompute Ц§іЦБй»оµДУпСФЈ¬ОЄБЛИГУГ»§ДЬ№»ОЮ·мЅУИл MaxCompute Ј¬ОТГЗТІЦ§іЦїЄФґПµНієГ¶аµД API Ј¬°ьАЁ spark API єН Hive API µИЎЈ
ЎЎЎЎЕъґ¦АнјЖЛг
ЎЎ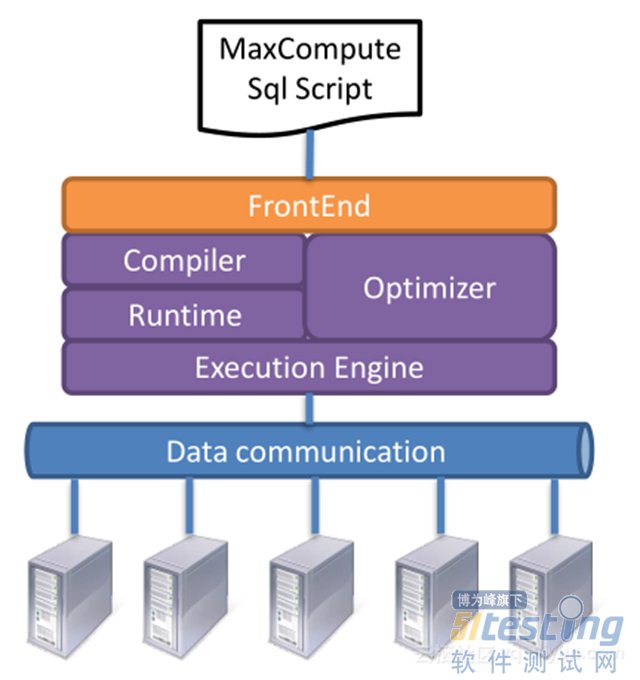
ЎЎЎЎДїЗ°Ј¬¶ФУЪ°ўАп°Н°НЙхЦБТµЅзАґЛµЈ¬ SQL АаРНµДЕъґ¦АнКЗЧоѕµдЧо№г·єµДУ¦УГБЛЈ¬ SQL Еъґ¦АнµДБчіМИзПВЈє
ЎЎЎЎУГ»§МбЅ»Т»МхАаЛЖ SQL µДЅЕ±ѕµЅ MaxCompute єуЈ¬ MaxCompute »б¶Ф SQL ЅЕ±ѕЅшРР±аТлІўУЕ»ЇЈ¬И»єуУГ Runtime ФЛРРЎЈ
ЎЎЎЎґуКэѕЭјЖЛг·юОс
ЎЎЎЎMaxCompute ТЄЧцґуКэѕЭјЖЛгµД·юОсЈ¬ІўІ»ПсТµЅзїЄФґµД hadoop Ўў spark МṩһМЧЅвѕц·Ѕ°ёЈ¬ОТГЗРиТЄМṩһёц 365 (Мм) x24 (РЎК±)µДёЯїЙїїЈ¬ёЯїЙУГµД№ІПнґуКэѕЭјЖЛг·юОсЎЈ
ЎЎЎЎДЗГґЈ¬УРКІГґєГґ¦ДШ?ЛьїЙТФЈє
ЎЎЎЎЁC К№УГГЕјчґуґуЅµµНЈ¬УГ»§І»УГ№ШРДФЛО¬Йэј¶µИ
ЎЎЎЎЁC №ІПнПёБЈ¶ИК№УГЧКФґЈ¬ґУ¶шЧцµЅµНіЙ±ѕЈ¬ёЯР§ВК
ЎЎЎЎґуКэѕЭјЖЛг·юОсЗїµчОИ¶ЁРФЈ¬УліЦРш·ўХ№Ц®јдґжФЪМмИ»µДГ¬¶ЬЎЈФЪТ»ёцОИ¶ЁФЛРРµДґуКэѕЭјЖЛг·юОсЙПёДЅшєН·ўІјРВ№¦ДЬѕНПсЎ°їХЦР»»іµЎ±Ј¬ФЪёЯЛЩ·ЙРРµД·Й»ъЙПМж»»ТэЗж¶шН¬К±ТЄ±ЈіЦЖЅОИ·ЙРРЈ¬ЖдЦРµДМфХЅДС¶ИїЙПл¶шЦЄЎЈ
ЎЎЎЎіЦРшёДЅшєН·ўІјЦРµДМфХЅ
ЎЎЎЎЎ¤ MaxCompute ГїМм¶јУР°ЩНтј¶ЧчТµЎЈИзєОДЬ№»ЖЅОИ°ІИ«Ј¬УГ»§ОЮёРЦЄµД·ўІјРВµД№¦ДЬ?ИзєО±ЈЦ¤РВ°ж±ѕµДОИ¶ЁРФЈ¬Г»УР bug Ј¬Г»УРРФДЬµД»ШНЛ?іцПЦОКМвєуИзєОДЬ№»їмЛЩЦ№ЛрµИµИ?
ЎЎЎЎЎ¤ Гж¶ФНвІїУГ»§Ј¬ФЪІвКФК±ИзєО±ЈЦ¤КэѕЭ°ІИ«їЙїїДШ?
ЎЎЎЎХл¶ФТФЙПМфХЅЈ¬ОТГЗМбіцФЪёЯїЙУГ·юОсПВіЦРшёДЅшєН·ўІјБЛТФПВјјКхКЦ¶ОАґїЛ·юЈє
ЎЎЎЎЁC MaxCompute Playback №¤ѕЯ
ЎЎЎЎЁC MaxCompute Flighting №¤ѕЯ
ЎЎЎЎЁC MaxCompute »Т¶ИЙППЯЈ¬ПёБЈ¶И»Ш№ц
ЎЎЎЎ±аТлЖчPlayback№¤ѕЯ
ЎЎЎЎMaxCompute ДїЗ°ЦчБчµДИФИ»КЗ SQL АаРНУ¦УГЈ¬ЖдЦР·ЗіЈ№ШјьµДДЈїйѕНКЗ±аТлУЕ»ЇЖчЈ¬ОТГЗРиТЄїмЛЩМбёЯОТГЗ±аТлЖчЎўУЕ»ЇЖчµД±нґпДЬБ¦Ј¬ТФј°РФДЬУЕ»ЇЛ®ЖЅЎЈ
ЎЎЎЎДЗГґЈ¬ИзєОДЬ№»±ЈЦ¤Йэј¶№эіМЦРГ»УРґуµД Regression ?
ЎЎЎЎГїМмУР 100 Нт + ёц job Ј¬ГїМм¶јФЪ±д»ЇЈ¬Из№ыИЛ№¤·ЦОцµД»°Ј¬Гїёц script ЅцРиТЄ 2 ·ЦЦУЈ¬РиТЄ91 ИЛДкЈ¬ХвКЗІ»ПЦКµµДЈ¬ЛщТФЈ¬ОТГЗїЄ·ўБЛ±аТлЖч Playback №¤ѕЯЎЈ
ЎЎЎЎPlayback №¤ѕЯУГАґЅвѕц±аТлЖчєНУЕ»ЇЖчµДІвКФСйЦ¤№¦ДЬЈ¬АыУГґуКэѕЭјЖЛгЖЅМЁµДФЛЛгДЬБ¦АґЧФОТСйЦ¤РВµД±аТлУЕ»ЇЖчЎЈ
ЎЎЎЎѕЯМеФАнИзПВЈє
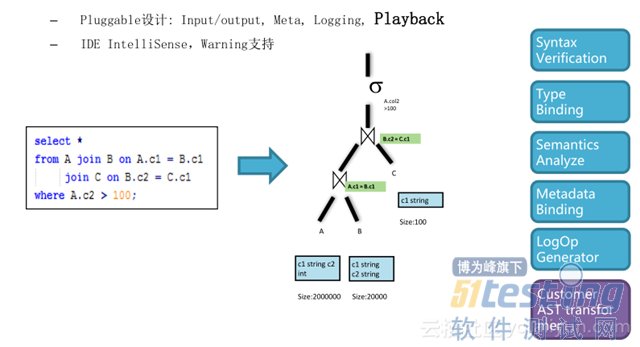
ЎЎЎЎ»щУЪ MaxCompute Зїґу¶шБй»оµД±аТлА©Х№ДЬБ¦Ј¬±аТлЖч»щУЪ AST µД±аТлЖчДЈРНЈ¬К№УГБЛѕµдµД Visitor ДЈКЅЎЈ SQL ЅЕ±ѕМбЅ»µЅПµНієу»бЅ« SQL ЅЕ±ѕЧЄ»ЇіЙійПуУп·ЁКчЈ¬ХэіЈЗйїцПВµДУп·ЁСйЦ¤єН·ЦОцµИКµПЦБЛ±кЧјµД visitor Ј¬ visitor ¶ФУ¦УЪ AST µДСйЦ¤µИА©Х№РФКЗ·ЗіЈєГµДЈ¬іэБЛ±кЧјµД visitor јУИлєуЈ¬»№їЙТФјУИлТ»Р©УРХл¶ФРФµДјмІйСйЦ¤ійПуУп·ЁКчµДРВ visitor Ј¬Ѕ«ХвР© visitor јУµЅУп·ЁКчЙПЈ¬ѕНїЙТФСйЦ¤РВµД±аТлЖчєНУЕ»ЇЖчЙъіЙіцАґµДёчЦЦёчСщµДІъіцКЗ·с OK Ј¬ТФґЛАґСйЦ¤РВµД±аТлЖчєНУЕ»ЇЖчµДДЬБ¦ЎЈ
ЎЎЎЎЧФОТСйЦ¤
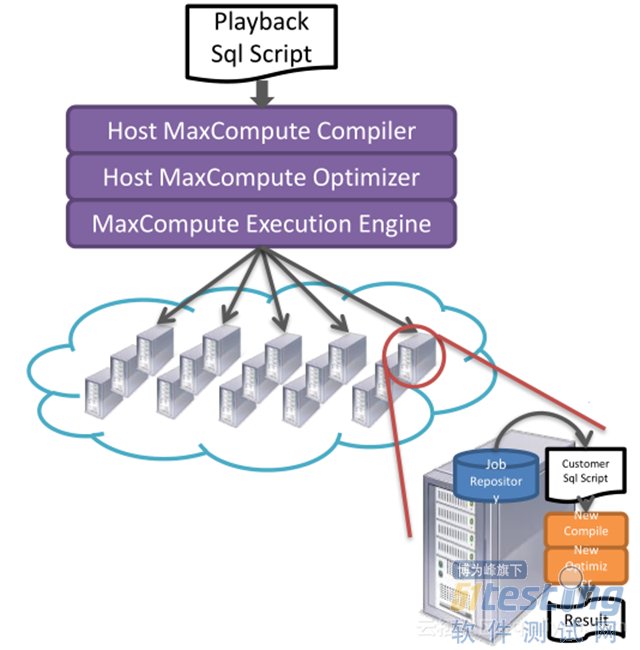
ЎЎЎЎХыёцСйЦ¤№эіМИзПВЈє
ЎЎЎЎ1. µ±УГ»§МбЅ»Т»Мх SQL ЅЕ±ѕ·ўёш MaxCompute Ј¬АыУГ MaxCompute ±ѕЙнБй»оКэѕЭґ¦АнУпСФАґ№№Фм·ЦОцИООс;
ЎЎЎЎ2. АыУГ MaxCompute ±ѕЙні¬ґу№жДЈјЖЛгДЬБ¦АґІўРР·ЦОцєЈБїУГ»§ИООсЈ¬Ѕ«Т»¶ОК±јдУГ»§ЧчТµійіц;
ЎЎЎЎ3. АыУГ MaxCompute Бй»оµД UDF Ц§іЦЗТБјєГµДёфАл·Ѕ°ёЈ¬ФЪ UDF ЦРАЖрґэІвµД±аТлЖчЅшРР±аТлЈ¬Ц®єуФЩЅшРРПкПёµДЅб№ы·ЦОцЎЈ
ЎЎЎЎХыёц№эіМ¶јФЪ MaxCompute НкЙЖµД°ІИ«МеПµ±Ј»¤ПВЈ¬±ЈХПУГ»§µДЦЄК¶ІъИЁЎЈ
ЎЎЎЎPlayback №¤ѕЯ»№УРЖдЛьєЬ·бё»µДЧчУГЈ¬±ИИзЈє
ЎЎЎЎЎ¤ ЅшРРРВ°ж±ѕµДСйЦ¤
ЎЎЎЎЎ¤ ѕ«И·ЦЖµјХТµЅґҐ·ўРВµДУЕ»Ї№жФтµД query Ј¬СйЦ¤ЖдІйСЇУЕ»ЇКЗ·с·ыєПФ¤ЖЪ
ЎЎЎЎЎ¤ ФЪУпТеІгГж¶ФУЪ query ЅшРРХыМеКэѕЭ·ЦОц
ЎЎЎЎЁC ¶ФПаУ¦µДУГ»§·ў warning НЖ¶ЇУГ»§ПВПЯ№эК±µДУп·Ё
ЎЎЎЎЁC ¶Ф query ХыМеЅшРР·ЦОцАґИ·¶ЁПВТ»ІЅїЄ·ўµДЦШµг
ЎЎЎЎЁC ЖА№АРВ°ж±ѕФЪІйСЇУЕ»ЇФЪЦґРРјЖ»®ЙПµДМбёЯіМ¶И
ЎЎЎЎFlighting №¤ѕЯ
ЎЎЎЎіэБЛ±аТлЖчєНУЕ»ЇЖчНвЈ¬БнНвУРТ»ёц№ШјьДЈїйѕНКЗЦґРРЖчЎЈДЗГґЈ¬ИзєО±ЈЦ¤ MaxCompute ФЛРРЖчКЗХэИ·ЦґРРµД?±ЬГвФЪїмЛЩµьґъЦРµДХэИ·РФОКМвЈ¬ґУ¶ш±ЬГвЦШґуµДКВ№К?Н¬К±Ј¬ИзєО±ЈЦ¤КэѕЭµД°ІИ«РФДШ?
ЎЎЎЎґ«Ні·ЅКЅСйЦ¤ФЛРРЖчЈ¬ЧоѕµдµДКЗУГІвКФјЇИєАґСйЦ¤Ј¬ёГ·ЅКЅСйЦ¤µДИ±µгИзПВЈє
ЎЎЎЎЁC µч¶И»тХЯ scalability µИ·ЅГжµДёДЅшНщНщРиТЄЅЁБўТ»ёцПаН¬№жДЈµДІвКФјЇИє
ЎЎЎЎГ»УРПаУ¦µДИООсёєФШЈ¬ОЮ·Ё№№Фм¶ФУ¦іЎѕ°
ЎЎЎЎКэѕЭ°ІИ«ОКМвЈ¬К№µГОТГЗРиТЄНСГфµД·ЅКЅґУЙъІъјЇИєНПКэѕЭ
ЎЎЎЎЁC ИЭТЧИЛОЄКиєцЈ¬ФміЙКэѕЭР№В¶·зПХ
ЎЎЎЎЁC НСГфКэѕЭїЙДЬФміЙУГ»§іМРт crash Ј¬ІўЗТНщНщІ»ДЬ·ґУіУГ»§ФЛРРіЎѕ°
ЎЎЎЎЁC ХыёцІвКФ№эіМИЯі¤Ј¬І»ДЬґпµЅІвКФµДДїµД

ЎЎЎЎЛщТФОТГЗТэИлБЛ flighting №¤ѕЯАґЧцІвКФєНСйЦ¤Ј¬Ѕ« 99% »ъЖчЧКФґК№УГПЯЙП°ж±ѕФЛРРЙъІъЧчТµЈ¬1% »ъЖчЧКФґУГАґОЄіМРтФ±ЙПФШµДІвКФ°ж±ѕЅшРРСйЦ¤ЎЈ
ЎЎЎЎЧКФґёфАл
ЎЎЎЎДЗГґЈ¬ФхГґ±ЈЦ¤ІвКФСйЦ¤µДЧчТµІ»ИҐУ°ПмПЯЙПЙъІъµДЧчТµДШ?ХвѕНРиТЄОТГЗНкЙЖЧКФґёфАлЈ¬ѕЯМе°ьАЁЈє
ЎЎЎЎЎ¤ CPU/Memory: ФцЗї cgroup Ј¬ИООсУЕПИј¶
ЎЎЎЎЎ¤ Disk ЈєНіТ»µДґжґў№ЬАнЈ¬ґжґўµДУЕПИј¶
ЎЎЎЎЎ¤ Network Јє Scalable Traffic Control
ЎЎЎЎQuota №ЬАн
ЎЎЎЎЛщТФОТГЗДЬ№»ФЪ±ЈХППЯЙПєЛРДТµОсРиЗуЗйїцПВЅшРР flighting µДІвКФЎЈ
ЎЎЎЎКэѕЭ°ІИ«
ЎЎЎЎґУКэѕЭ°ІИ«ЅЗ¶ИАґЛµЈ¬ОТГЗµДІвКФІ»РиТЄИЛ№¤ёЙФ¤ЅшРРКэѕЭНСГф; Flighting µДИООсµДЅб№ыІ»ВдЕМЈ¬¶шКЗЦ±ЅУ¶ФЅУ·ЦОцИООсІъЙъІвКФ±ЁёжЈє
ЎЎЎЎЁC Ѕб№ыХэИ·РФЈє MD5 јЖЛгЈ¬ёЎµгµИІ»И·¶ЁРФАаРНµДґ¦Ан
ЎЎЎЎЁC ЦґРРРФДЬµД·ЦОцЈє straggler Ј¬ data-skew Ј¬ schedule quality
ЎЎЎЎ»Т¶ИЙППЯ

ЎЎЎЎSQL µД№ШјьДЈїйИз±аТлУЕ»ЇєНЦґРР¶јїЙТФµГµЅУРР§ІвКФєНСйЦ¤Ј¬ЅУПВАґѕНїЙТФЙППЯБЛЈ¬ЙППЯК±ТІ»бУРєЬґу·зПХЈ¬ТтґЛЈ¬ОТГЗКµРР»Т¶ИЙППЯЎЈ°ґХХИООсµДЦШТЄРФЅшРР·Цј¶Ј¬Ц§іЦПёБЈ¶И·ўІјЈ¬ІўЗТЦ§іЦЛІК±»Ш№цЈ¬їШЦЖ·зПХµЅЧоРЎЎЈ
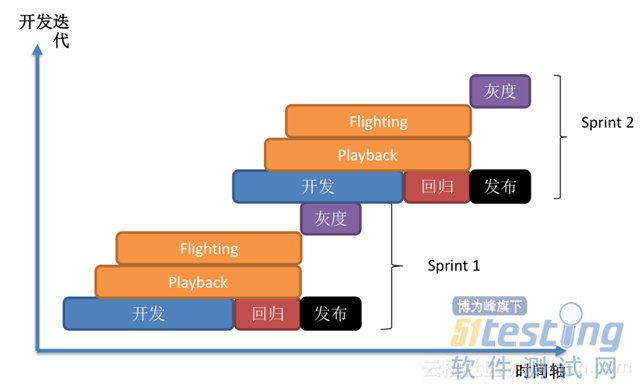
ЎЎЎЎїЄ·ўРВ№¦ДЬєуЧц»Ш№йЈ¬»Ш№йєу·ўІјЈ¬їЄКјК±НщНщУРРВ№¦ДЬєуЈ¬ѕНЅшРРСйЦ¤Ј¬Из№ыРВ№¦ДЬКЗХл¶Ф±аТлЖчЎўУЕ»ЇЖчЈ¬ѕНУГ playback СйЦ¤Ј¬Хл¶Ф Runtime ѕНУГ flighting СйЦ¤Ј¬ЛщУРІвКФСйЦ¤ЅбКшєуЈ¬ѕНµЅ»Т¶И·ўІјЅЧ¶ОЈ¬Ц±µЅЛщУРИООс°Щ·Ц°Щ·ўІјЙППЯєуЈ¬ОТГЗѕНИПОЄХвТ»ґОїЄ·ўµьґъКЗіЙ№¦µДЈ¬ТФґЛАаНЖЈ¬І»НЈµДПтЗ°СЭЅшЈ¬јИДЬ±ЈЦ¤·юОсїЙїїОИ¶ЁФЛРРµДН¬К±Ј¬Ѕ«ОТГЗµДРФДЬМбЙэЈ¬ТФВъЧгУГ»§µДёчЦЦРиЗуЎЈ












