

经常,在应用程序的业务逻辑中存在大量的这样的接口:他们接受不同的输入,然后进行或验证,或处理,进而完成相同的流程。比如网站的登录入口,用户名和密码都有长度的限制,同时也具有是否允许特殊字符的限制等,所以在我们进行其单元测试的过程中,根据不同长度的用户名和密码,以及不同的字符组合,只需要提供相同的测试代码结构,就能完成测试,不同的仅仅测试数据与期望值,但是因为每一个测试方法中的输入参数不同,我们必须为每一个输入组编写单独的测试用例,从而产生大量冗余代码,十分不便于维护。幸好,本文所述的 Feed4JUnit 良好的解决了数据与代码分离的问题,Feed4JUnit是 JUnit测试框架的扩展,它通过操作来自于文件以及不同的数据源的测试数据,使您的单元测试变得更容易编写与维护。
一、使用工具
Eclipse+Java+httpclient+feed4junit+Junit4
二、Feed4JUnit 的下载及安装
1. Feed4JUnit 是开源的测试组件,您可以从如下链接下载最新版本:
http://sourceforge.net/projects/feed4junit/files/
2. 解压下载的 zip包,复制整个 lib文件夹到您的 Java项目的根目录,如图 1:

图 1. 复制 lib 到项目根目录
3. 选定项目,右键选择项目的属性,然后通过 Add JARs将步骤 2中 lib 文件夹下的所有 Jar添加到项目的 BuildPath下,如图2
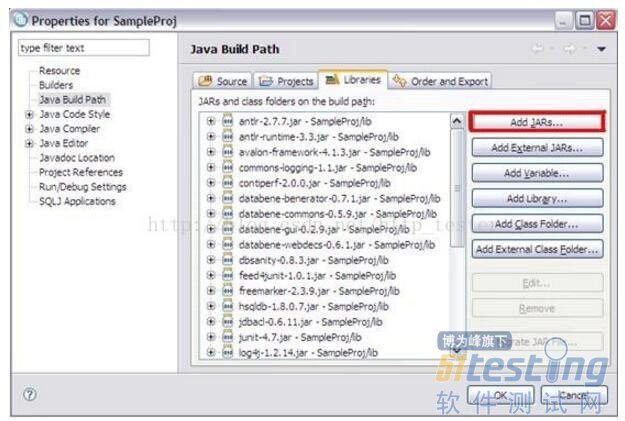
图 2. 添加 Jar 到 Build Path
三、使用 Feed4JUnit 实现数据与代码分离的测试
Feed4JUnit 的数据源可以包括以下几种类型-文件 (CSV或者Excel )、数据库、自定义数据源。
Feed4JUnit使用一个特殊的运行类Feeder.class,用来支持与标识参数化测试,如果您想要编写数据与代码分离的测试脚本,必须在您的测试类上增加注释@RunWith(Feeder.class)。同时,您需要使用@Test来标示您实现测试的方法,并且使用@Source来声明和接收数据源的数据,基本的代码结构如清单3所示:
清单 3. 测试代码结构
package Living; import static org.junit.Assert.*; import org.databene.benerator.anno.InvocationCount; import org.databene.benerator.anno.Source; import org.junit.After; import org.junit.AfterClass; import org.junit.Before; import org.junit.BeforeClass; import org.junit.Test; import org.junit.runner.RunWith; import Pub.LivingPub; import org.databene.feed4junit.Feeder; @RunWith(Feeder.class) public class PushTest{ @BeforeClass public static void setUpBeforeClass()throws Exception { } @AfterClass public static void tearDownAfterClass()throws Exception { } @Before public void setUp() throws Exception { } @After public void tearDown() throws Exception { } @Test // @InvocationCount(1) //指定测试的次数 @Source("D:/data/Living/push.xlsx")//指定测试的数据源 public void pushTest(String cases,StringclassroomId,Stringname, String loginToken,StringquestionUrl,StringquestionId,Stringcorrect, String courseLevelId,Stringanswers,booleanexpected) { assertEquals(expected, LivingPub.push(cases,classroomId,name,loginToken,questionUrl,questionId,correct,courseLevelId,answers)); } } |
以文件作为数据源
Feed4JUnit支持从 CSV或者 Excel文件里面读取数据作为输入,这里我们以Excel文件为例。
1. 在D:/data/Living/目录下创建push.xlsx数据文件,样例数据如图3,默认情况下,第一行会以列名存在,在运行过程中不会作为数据读取。
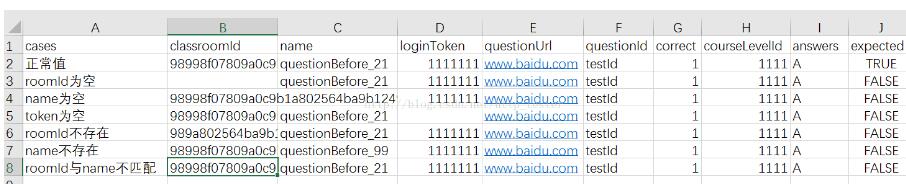
图 3. Excel 数据源
2. 创建测试类并在接收数据的测试方法上声明数据源为@Source("D:/data/Living/push.xlsx"),Excel中的数据在传递过程中会自动按照列与测试方法的参数的位置顺序进行匹配,并以行作为一个单位读取并传递给测试方法体。比如图3中的 cases列的值会做为方法的第一个参数传入方法体中,classroomId列的值会作为方法的第二个参数,以此类推。在测试进行过程中,首先在Excel文件中读取一行(包含三列),接着按照位置顺序将数据传递到方法体中(每列按顺序对应一个参数)进行执行,执行完成后读取Excel中的下一行进行相同流程的测试,其原理与Java中的迭代器十分类似。请注意当数据文件中数据的列数小于测试方法参数的个数的时候,测试会因为位置不匹配而失败。
3. 运行测试,因为 Feed4Junit是 JUnit的扩展,所以运行方式与 JUnit完全相同,即以 JUnit运行即可,运行结果如图 4所示,我们可以看到,Data.xls中的数据已全部传入测试方法并运行。
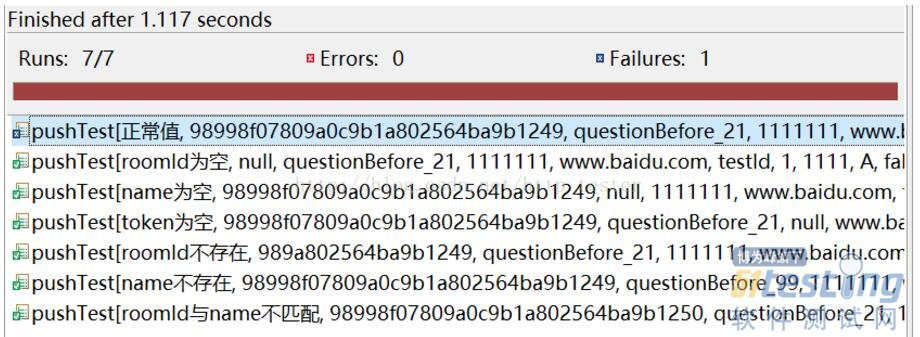
图 4. 运行结果示例












