

一、前言
在上一篇博文中,我们的爬虫面临着一个问题,在爬取Unsplash网站的时候,由于网站是下拉刷新,并没有分页。所以不能够通过页码获取页面的url来分别发送网络请求。我也尝试了其他方式,比如下拉的时候监控http请求,看看请求是否有规律可以模拟。后来发现请求并没有规律,也就是不能够模拟http请求来获取新的数据(也可能是我水平有限,哪位童鞋找到了规律一定要告诉我哦)。那么就只有模拟下拉操作了。
想要模拟下拉操作,我们需要用到两个工具,一个是PhatomJs,一个是Selenium。
PhatomJS其实就是一个没有界面的浏览器,最主要的功能是能够读取js加载的页面。
Selenium实质上是一个自动化测试工具,能够模拟用户的一些行为操作,比如下拉网页。
一直有个说法,Python + PhatomJS + Selenium 是爬虫的无敌三件套,基本能够实现所有爬虫需求。
OK,我们分别介绍下他们的使用,然后开始我们的实战。
二、运行环境
我的运行环境如下:
· 系统版本
Windows10。
· Python版本
Python3.5,推荐使用Anaconda 这个科学计算版本,主要是因为它自带一个包管理工具,可以解决有些包安装错误的问题。去Anaconda官网,选择Python3.5版本,然后下载安装。
· IDE
我使用的是PyCharm,是专门为Python开发的IDE。这是JetBrians的产品,点我下载。
三、PhatomJS
1. 简介
PhatomJS是一个WebKit内核的浏览器引擎,它能像浏览器一样(它就是一个浏览器,只不过没有界面)解析网页,以及运行JavaScript脚本。
迄今为止,我们的实战小爬虫只是在模拟http请求,然后获取response,从response中解析HTML代码获得想要的数据。但是,网页中有些数据是用js动态加载的,这样,我们使用使用http请求获得的数据中并不包含js动态加载的内容。比如我在本系列的第一篇博文中请求了一下网易云音乐的网站,本来想用网易云音乐做实战示例的(我的设计师小伙伴儿的另一个需求),不过由于它是由js动态加载的,用不到requests库,所以就先以Unsplash网站为实例了。写完Unsplash网站的爬虫后就开始网易云音乐的实战!
那么,怎么判断一个网站的内容是不是js动态加载的呢?
打开网易云音乐,在页面上点击右键-->View page source。会弹出一个新窗口,在新窗口中搜索你想要爬取的内容,发现搜不到。那就肯定是js动态加载的了。
比如看下图中的选中图片,下面有文字:“影视歌曲|重新演绎经典 听翻唱焕发新生命力”。
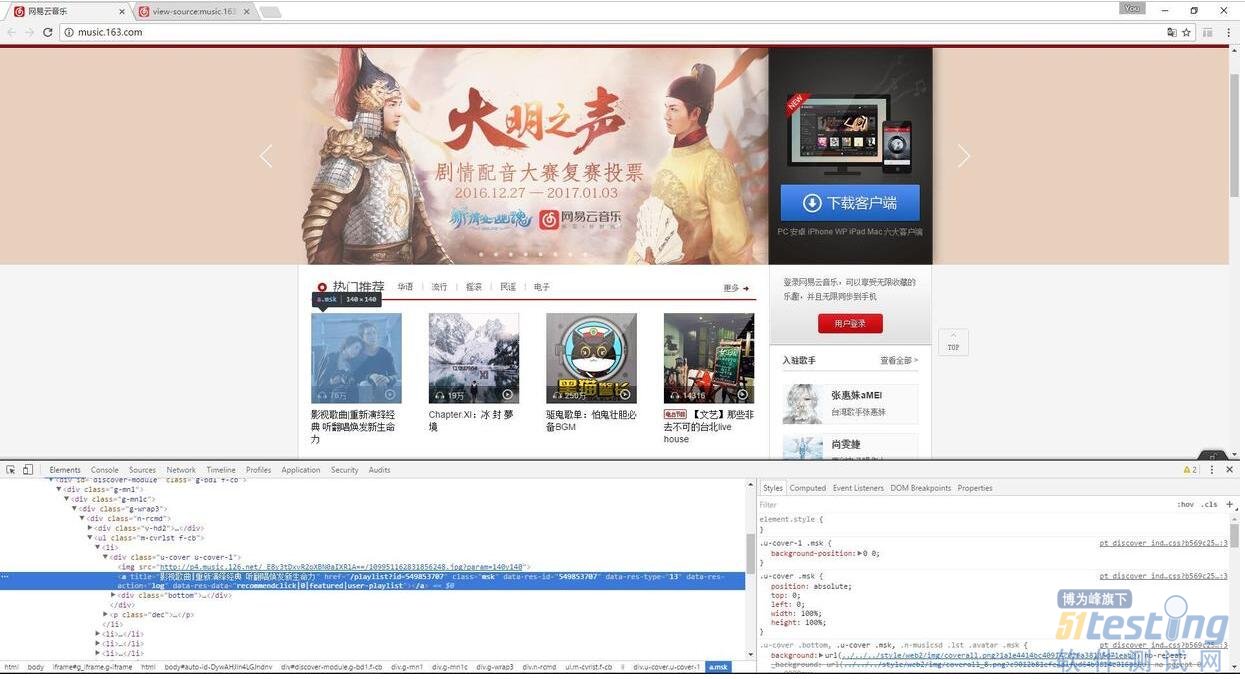
我们在View page source页面搜索该内容,发现搜索不到,可见这部分内容是由js动态加载的。

好了,进入正题,来看看PhatomJS如何使用。
2. 安装 PhatomJS
PhatomJS 不能使用conda install 或者pip install 来安装。需要去官网下载,选择你的系统版本。下载完成的是一个压缩包,解压到你想存放的目录(我放在了“C:\Program Files\” 目录)。
接下来需要把PhatomJS配置成环境变量,这样就可以直接调用了。
步骤:
1). 按win+E快捷键打开文件资源管理器“,在左侧的“此电脑”上点击右键,选择“属性”。
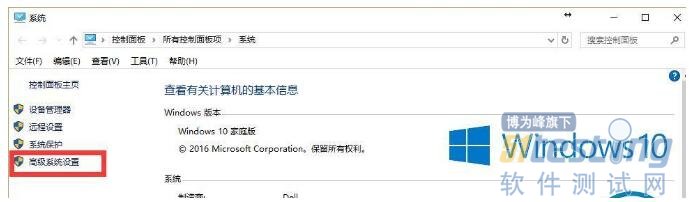
2). 在打开的窗口中左侧,点击“高级系统设置”。
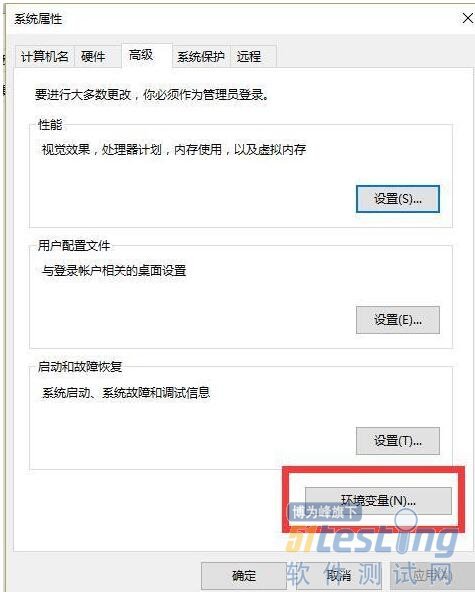
3). 在弹出的窗口中点击“环境变量”。
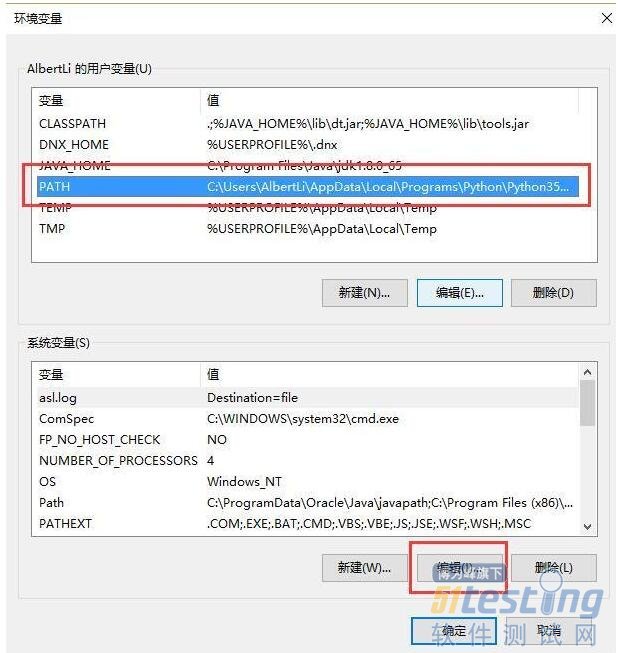
4). 在新窗口中选择“PATH”,在下方点击编辑按钮。
5). 把phatomjs.exe所在的目录添加到path中即可。
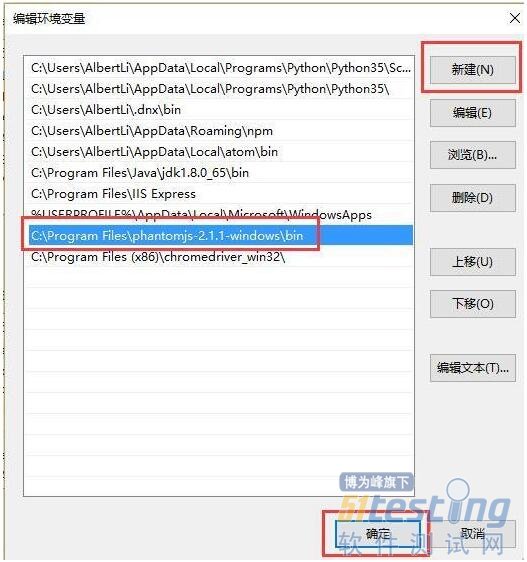
这样,安装过程就搞定了。












