

这两天趁着有时间,我疯狂的码字了~~
背景
我们公司是做人工智能平台的,什么是人工智能呢? 大数据+机器学习。大数据运行的基本就不快。机器学习算法运行起来也是慢的让人泪流满面。在我们的集群配置下,我使用一个5M的数据从数据引入到数据处理,特征工程,模型训练和评估报告等等一整套线下模型调研流程要10分钟左右。所以单线程执行测试用例是不靠谱的。而UI自动化在一台机器上只能是单线程执行。所以多台机器同时运行case的分布式处理方案呼之欲出。
原理
原理其实很简单。 我分步骤说一下
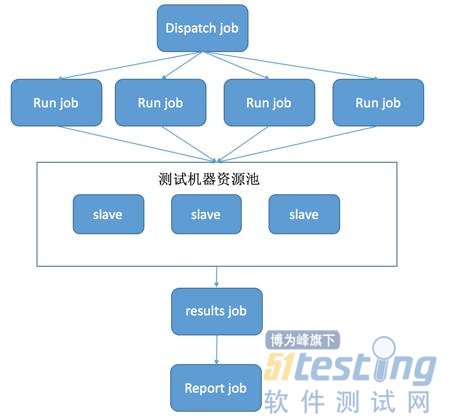
1、我们是用jenkins做CI工具的。所以通过jenkins的slave机制添加多台slave机器当做测试机。配置测试机在同一时间只能运行一个任务,也就是不能并发执行。
2、创建一个可以并发的job然后把步骤一中的测试机注册到这个job中,我们姑且叫这个job为run job。run job在触发构建的时候在所有的测试机中查询空闲的测试机,如果有空闲的就到这台机器上执行测试任务。如果没有空闲的机器就等待直到有机器空闲。
3、我们把测试用例分成不同的group,然后创建一个分发任务的job,我们姑且叫这个job为dispatch job。dispatch job中配置一段shell脚本,通过jenkins API的方式调用run job并把group作为参数传递过去。这样我们在dispatch job中调用了N次run job 也就是在不同的机器上同时跑不同的group。
4、接下来我们要解决测试报告的问题。我要创建一个归集所有测试结果的job,我们姑且叫它为results job。results job会拉取所有run job的测试结果并保存到特定位置
5、然后我们创建一个merge测试结果并生成测试报告的job,我们姑且叫它为report job。
总结一下我们需要多台测试机器和4个job。分别是dispatch job,run job,results job和report job。 大概的样子如下:
配置slave 测试机
这个比较简单,大家可以到网上找详细的教程。只需要记得创建的node要统一一个label比较好管理。如下:

dispatch job
这个job基本就是由shell脚本构成的,通过shell来调用jenkins的API。如下:
#!/bin/sh #输出构建者的信息 echo $BUILD_USER_EMAIL $BUILD_USER > tigger_user_info #检查是否有任务还在跑 STATUS=`curl -v --silent "http://jenkins.4paradigm.com/job/prophet-test-run/api/json?tree=builds\[result\]" 2>&1 | grep -o "{\"result\":null}"` #测试任务URL RUN_JOB_URL="http://jenkins.4paradigm.com/job/prophet-test-run/buildWithParameters?token=prophet" if [ "$STATUS" = "" ]; then curl "$RUN_JOB_URL&env=$env&branch=$branch&group=atomTest.xml" curl "$RUN_JOB_URL&env=$env&branch=$branch&group=model_train.xml" curl "$RUN_JOB_URL&env=$env&branch=$branch&group=dataload.xml" curl "$RUN_JOB_URL&env=$env&branch=$branch&group=smoke.xml" printf "下发测试任务成功!\n" else printf "测试服务器繁忙,下发测试任务失败!\n" exit -1 fi #任务下发成功后删除上次构建产生的结果 rm -rf ../../prophet-send-report/workspace/allure-results/* |
逻辑比较简单,首先检查当前还有没有run job在执行,如果有,那么执行失败。其实应该等待的执行结束的,只是暂时还没加这段逻辑。如果没有run job在执行。那么调用run job的API 把测试任务分发下去。其中要把一些参数传递过去。例如运行环境,测试代码分支,测试用例的group
run job
这个job比较常规,配置有点多我不详细的列举了。无非就是配置git lab,拉取测试代码并build 运行测试。其中slave测试机是注册在这个job里的。有一个需要注意的地方是run job运行结束后触发下一个results job,需要传递一个比较重要的参数-- build number。因为下一个job 需要知道run job的build number好去归集测试结果。如下:
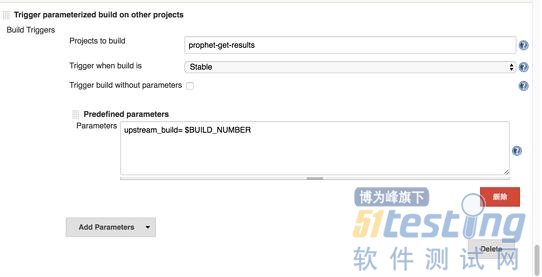
对了还有一个特别重要的东西。为了要把测试结果从slave测试机上拉到jenkins上。我们需要剑走偏锋。配置如下:

其实这个时候我们并不希望在run job上就生成html 的report,我们指向的目录也不是report的目录。而是存放测试结果的xml文件的目录。jenkins默认是不会从slave测试机上拉取这些文件的。为了让jenkins拉取这些文件,所以我们利用这个html report插件强行让jenkins把他们拉取上来。












