

针对自己曾经经历过的一道面试题,那些情况不走索引,于是搜索网络和书籍的一些资料,整理如下:
1、查询谓词没有使用索引的主要边界,换句话说就是select*,可能会导致不走索引。
比如,你查询的是SELECT*FROMTWHEREY=XXX;假如你的T表上有一个包含Y值的组合索引,但是优化器会认为需要一行行的扫描会更有效,这个时候,优化器可能会选择TABLEACCESSFULL,但是如果换成了SELECTYFROMTWHEREY=XXX,优化器会直接去索引中找到Y的值,因为从B树中就可以找到相应的值。
2、单键值的b树索引列上存在null值,导致COUNT(*)不能走索引。
如果在B树索引中有一个空值,那么查询诸如SELECTCOUNT(*)FROMT的时候,因为HASHSET中不能存储空值的,所以优化器不会走索引,有两种方式可以让索引有效,一种是SELECTCOUNT(*)FROMTWHEREXXXISNOTNULL或者把这个列的属性改为notnull(不能为空)。
3、索引列上有函数运算,导致不走索引
如果在T表上有一个索引Y,但是你的查询语句是这样子SELECT*FROMTWHEREFUN(Y)=XXX。这个时候索引也不会被用到,因为你要查询的列中所有的行都需要被计算一遍,因此,如果要让这种sql语句的效率提高的话,在这个表上建立一个基于函数的索引,比如CREATEINDEXIDXFUNTONT(FUN(Y));这种方式,等于Oracle会建立一个存储所有函数计算结果的值,再进行查询的时候就不需要进行计算了,因为很多函数存在不同返回值,因此必须标明这个函数是有固定返回值的。
4、隐式转换导致不走索引。
索引不适用于隐式转换的情况,比如你的SELECT*FROMTWHEREY=5在Y上面有一个索引,但是Y列是VARCHAR2的,那么Oracle会将上面的5进行一个隐式的转换,SELECT*FROMTWHERETO_NUMBER(Y)=5,这个时候也是有可能用不到索引的。
5、表的数据库小或者需要选择大部分数据,不走索引
在Oracle的初始化参数中,有一个参数是一次读取的数据块的数目,比如你的表只有几个数据块大小,而且可以被Oracle一次性抓取,那么就没有使用索引的必要了,因为抓取索引还需要去根据rowid从数据块中获取相应的元素值,因此在表特别小的情况下,索引没有用到是情理当中的事情。
6、cbo优化器下统计信息不准确,导致不走索引
很长时间没有做表分析,或者重新收集表状态信息了,在数据字典中,表的统计信息是不准确的,这个情况下,可能会使用错误的索引,这个效率可能也是比较低的。
7、!=或者<>(不等于),可能导致不走索引,也可能走INDEXFASTFULLSCAN
例如selectidfromtestwhereid<>100
8、表字段的属性导致不走索引,字符型的索引列会导致优化器认为需要扫描索引大部分数据且聚簇因子很大,最终导致弃用索引扫描而改用全表扫描方式
由于字符型和数值型的在insert的时候排序不同,字符类型导致了聚簇因子很大,原因是插入顺序与排序顺序不同。详细点说,就是按照数字类型插入(1..3200000),按字符类型('1'...'32000000')t排序,在对字符类型使用大于运算符时,会导致优化器认为需要扫描索引大部分数据且聚簇因子很大,最终导致弃用索引扫描而改用全表扫描方式。
下面展示测试结果,
两个表的数据类型相似(只是ID字段类型不同),各插入了320万数据,ID字段范围为1~3200000。
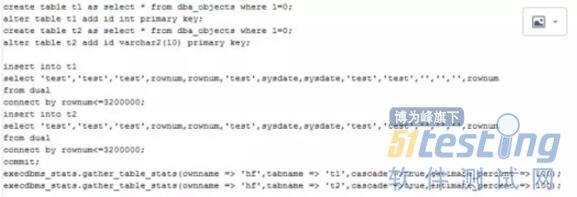
模拟场景
相关代码如下:
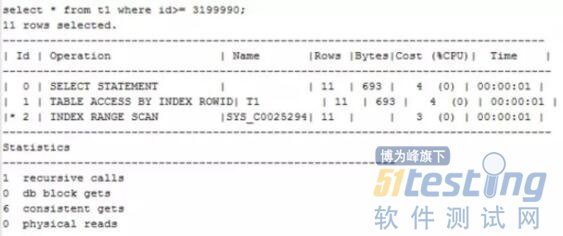
对于普通的采用数值类型的字段,范围查询就是正常的索引范围扫描,执行效率很高。

对于文本类型字段的表,范围查询就是对应的全表扫描,效率较低是显而易见的。
解决方法













