

综述:
众观很多的缺陷管理系统,都是为了更加合理的帮助开发进行缺陷管理。没有对见到的事物有充分的度量或适当的准则去判断、评估和决策,这样是无法进行优秀的管理。这就需要软件缺陷度量数据分析,度量就是对事物属性的量化的过程,但它不能对未来可能发生的缺陷进行预测,所以我们应用数据挖掘技术到软件缺陷度量中。对未来可能发生的缺陷进行分析预测,得出可能出现高缺陷数的模块。帮助管理层、开发与测试人员能预见性了解那些模块有潜在的严重缺陷,发现或者采取有效手段预防缺陷,不断改进软件开发过程。
下面先对什么是软件缺陷度量及预测、数据挖掘的概念与方法论、模糊聚类挖掘算法、自动收集数据做些简单的说明。
什么是软件缺陷度量及预测:
度量是根据一定的规则,将数字或符号赋予系统、构件、过程等实体的特定期属性,从而使我们能清晰地理解该实体及其属性的量化表示。简而言之,度量就是对事物属性的量化表示。
缺陷度量是软件度量的一部分,其本身并不能发现缺陷、剔除缺陷,但是有助于这些问题的解决。
缺陷度量就是对项目过程中产生的缺陷数据进行采集和量化。将分散的缺陷数据统一管理,使其有序而清晰,然后通过采用一系列数学函数,对数据进行处理,分析缺陷密度和趋势等信息,从而提高产品质量和改进开发过程。一般来说,在软件质量保证过程中,需要度量的缺陷数据包括6大类缺陷发现手段发现所有缺陷。如测试相关的缺陷、成本数据
测试任务完成情况、测试规模数据、测试结果数据(包括缺陷数据,覆盖率数据)。
那我们要怎么确定这些缺陷度量值呢?有些专家提出按照如下表所示的思路确定组织整体或者项目组、个体使用哪些缺陷度量元。
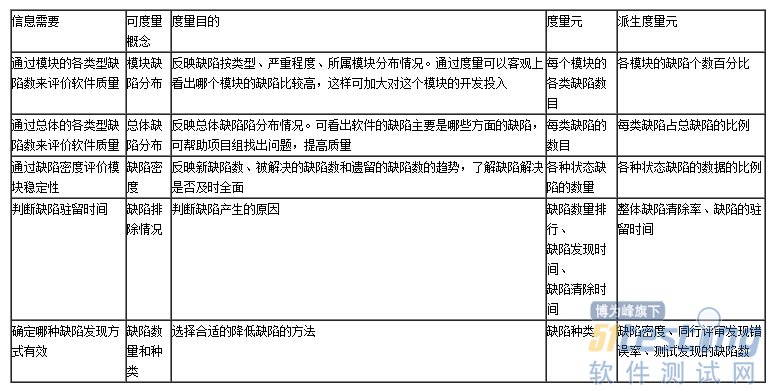
通过这些缺陷度量,我们可以对现有的缺陷进行管理分析,帮助提高改进软件质量。但这些远远还不够,因为越早发现bug,最终所发费的成本越少,所以可以测见性发现缺陷受到很大的重视。 软件缺陷预测是根据易于获得的软件产品统计度量,预测软件产品可能发生的缺陷数量或软件模块是否具有较高的缺陷风险的方法。是从常有缺陷数据中发现明确的规律,对软件当前系统和历史数据做出分析,对未来可能发生的缺陷进行分析预测。新系统通过与当前软件系统的测试数据和估算出的数据相比较,就会得知开发的系统的程序的质量情况。
那么什么是数据挖掘呢?
数据挖掘:
数据挖掘是从大量数据中提取出隐含的过去未知的有价值信息的科学。并把挖掘出来有价值的信息应用到业务流程中,从而达到业务目标的实现。要实现这个过程,不仅需要数据挖掘的各种算法,还有很多其它决定性的因素,如商业问题如何界定、数据如何选取、生成的模型如何嵌入到现有的业务流程等问题,都将直接影响数据挖掘是否能取得成功。所以行业提出了标准方法CRISP-DM(cross-industry standard process for data mining), 即为"跨行业数据挖掘标准流程":从商业理解(business understanding)—数据理解(data understanding)—数据准备(datapreparation)—建立模型(modeling)—模型评估(evaluation)—结果部署(deployment)。这个过程是循环往复的探索过程。
该模型将一个KDD工程分为6个不同的,但顺序并非完全不变的阶段(如下图所示)。
1: businessunderstanding: 即商业理解. 在第一个阶段我们必须从商业的角度上面了解项目的要求和最终目的是什么. 并将这些目的与数据挖掘的定义以及结果结合起来。
2.dataunderstanding: 数据的理解以及收集,对可用的数据进行评估。
3: datapreparation: 数据的准备,对可用的原始数据进行一系列的组织以及清洗,使之达到建模需求。
4:modeling: 即应用数据挖掘工具建立模型。
5:evaluation: 对建立的模型进行评估,重点具体考虑得出的结果是否符合第一步的商业目的。
6: deployment:部署,即将其发现的结果以及过程组织成为可读文本形式.(数据挖掘报告)
工具算法介绍:
建模可以用SPSS、SAS、R(开源软件)软件,IBM SPPS Statistics 作为全球最出色的统计分析软件之一,界面友好,使用简单,功能强大,可以编程,且有提供图形化模型与快速可视化报告展示,上手较快。SAS,是全球商业智能和分析软件与服务领袖,功能强大,可编程,是最难掌握的软件之一。R是一个自由、免费、源代码开放的软件,处理灵活,但对编程要求较高。
这里我们使用容易入手的SPSS工具来对度量值计算分析,当然工具只是手段,关键是挖掘的思想。
用于预测模型有模糊聚类、神经网络的测试模型、还有新型的贝叶斯网络模型。对比这些模型,模糊聚类是没有预先定义的分类来表明数据集中于哪个类;神经网络模型是反映人脑功能的基本特征,自学习高度复杂的非线性学习过程;新型的贝叶斯网络模型是基于概率推理的图形化网络,适合解决不定性问题。结合这些模型完全可以满足我们的挖掘需求。












