

然后我们对其赋值:
UPDATE dbo.EAVTable SET SomeData=LEFT(CAST(Value AS VARCHAR(1)),1)
现在当你执行用PIVOIT运算符的同个查询时(在那somedata列都有非NULL值),你会拿回完全不同的结果,因为排序阶段现在是在RecordID和SomeData列(我们刚加的)上。
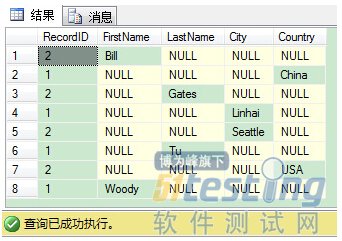
相比如果我们重新执行我们刚开始写的手工T-SQL查询会发生什么。它还是返回同样正确的结果。这是在SQL Server里,PIVOT运算符的其中一个最大的副作用:分组元素不能明确定义。为了克服这个问题,最佳实践是使用只返回需要列的表表达式。使用这个方法,如果你随后修改表架构还是没有问题,因从表表达式默认情况下额外的列还是没有返回。我们来看下列的代码:
-- Use a table expression to state explicitly which columns you want to -- return from the base table. Therefore you can always control on which -- columns the PIVOT operator is performing the grouping. SELECT RecordID, FirstName, LastName, City, Country FROM ( -- Table Expression SELECT RecordID, Element, Value FROM EAVTable ) AS t PIVOT(MAX(Value) FOR Element IN (FirstName, LastName, City, Country)) AS t1 GO |
从代码里可以看到,我通过一个表表达式输送给PIVOT运算符。而且在表表达式里,你从表里只选择需要的列。这就意味着以后你可以修改表架构也会破坏PIVOT查询的结果。
小结
我希望这篇文章已向你展示了在SQL Server里,为什么PIVOT运算符是非常危险的。这个语法本身带来了非常高效的代码,但作为副作用你不能直接指定分组元素。因次你应该确保使用一个表表达式来定义输送给PIVOT运算符的列来保证给出结果的确定性。
用PIVOT运算符你有什么经历?你是否喜欢它?如果你不喜欢它,你想要什么改变?












