

关于正态分布的相关理论知识,参考大数定律,和更有用些的强大数定律,以及分布函数的相关术语(感谢伯努力、高斯等数学世家,让我看公式看得泪流满面,好在即使看不懂,对我们理解样本容量的影响也不是很大)。
分母看完了,下面是分子。 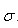 是总体标准差,
是总体标准差, 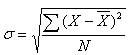 。
。  叫做总体方差。
叫做总体方差。
这里涉及到一堆子公式,且这些公式本身还有一些其他形式的推导和变形(这里就不多说了),所以也可以理解为什么书本上总是把样本容量估算放到后面几章才讲了。
换句话说,在确定了置信度、总体标准差和样本极限误差之后,我们就可以计算出样本容量了。那么总体标准差如何获得呢?我们可以在调查前先抽取少量的样本,得到总体标准差的估计,然后代入公式中,得到下一步抽样所需样本量n。
比如以下列出一组已调查好的数据:
| 1 | 3778593 |
| 2 | 5027681 |
| 3 | 5587816 |
| 4 | 5868831 |
| 5 | 6373435 |
| 6 | 6604816 |
| 7 | 6598222 |
| 8 | 6497155 |
| 9 | 6777191 |
| 10 | 6808727 |
可以得到总体标准差的近似值为(968096.8445),我们取置信度为95%,查表得Z=1.96,且假设样本的极限误差不超过样本平均值(5992246.674)的5%,也就是299612.3337。那么代入公式我们可以得到:
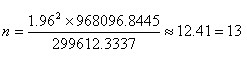 (样本数必须取整,且必须大于计算值)
(样本数必须取整,且必须大于计算值)
那么,我们对于上述数据,应该至少再顺序测出3个样本才能满足极限误差和置信度的要求。从上面这个例子也可以看出,置信度越大,所需测试的样本数将会越大。反之,保持置信度不变,极限误差越小,所需样本数也将越多。
从通俗的角度来讲,你要求我越精确(极限误差)越可靠(置信度)的告诉你数据之间到底有何关联,那么你就越是必须提供大量的样本(样本容量)来让我分析,这很符合现实世界的客观规律,只是当这些现象用数学语言来描述起来的时候,往往就会让人汗流浃背并且泪流满面了。
样本容量会影响到整个测试周期所需工作量的估算,样本数过多,显然会耗费大量用于测试的人力物力,样本数过少,又会使测试结果不够精确可靠。此外,假设有两个不同的测试对象,两者的规模不同,例如云计算包含的机器数量不同,一个是1万台,另一个是1千台,在这两个不同规模的系统上测试同一个产品,我们可能理所当然的认为样本数是会不同的,但通过上述的公式,我们可以得知样本数是完全相同的。这意味着,对于小规模的系统来说,所需的样本数不会比大规模系统更少,大规模系统所需样本数也不会比小规模系统更多,这里的差别在于,样本之间的间距将会依规模而不同。
当然,这仅仅只是抽样而已,对于获取数据后的分析,才是这个备忘录需要强烈关注的难点。












