

分类
分布式网络爬虫包含多个爬虫,每个爬虫需要完成的任务和单个的爬行器类似,它们从互联网上下载网页,并把网页保存在本地的磁盘,从中抽取URL并沿着这些URL的指向继续爬行。由于并行爬行器需要分割下载任务,可能爬虫会将自己抽取的URL发送给其他爬虫。这些爬虫可能分布在同一个局域网之中,或者分散在不同的地理位置。
根据爬虫的分散程度不同,可以把分布式爬行器分成以下两大类:
1、基于局域网分布式网络爬虫:这种分布式爬行器的所有爬虫在同一个局域网里运行,通过高速的网络连接相互通信。这些爬虫通过同一个网络去访问外部互联网,下载网页,所有的网络负载都集中在他们所在的那个局域网的出口上。由于局域网的带宽较高,爬虫之间的通信的效率能够得到保证;但是网络出口的总带宽上限是固定的,爬虫的数量会受到局域网出口带宽的限制。
2、基于广域网分布式网络爬虫:当并行爬行器的爬虫分别运行在不同地理位置(或网络位置),我们称这种并行爬行器为分布式爬行器。例如,分布式爬行器的爬虫可能位于中国,日本,和美国,分别负责下载这三地的网页;或者位于CHINANET,CERNET,CEINET,分别负责下载这三个网络的中的网页。分布式爬行器的优势在于可以子在一定程度上分散网络流量,减小网络出口的负载。如果爬虫分布在不同的地理位置(或网络位置),需要间隔多长时间进行一次相互通信就成为了一个值得考虑的问题。爬虫之间的通讯带宽可能是有限的,通常需要通过互联网进行通信。
大型分布式网络爬虫体系结构图
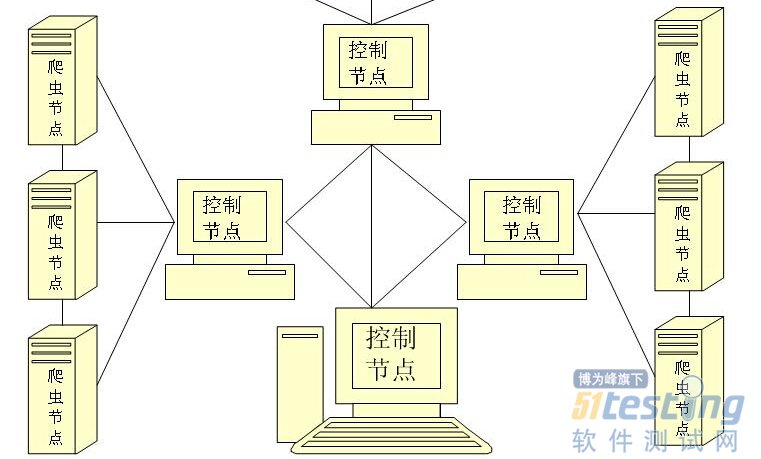
分布式网络爬虫是一项十分复杂系统。需要考虑很多方面因素。性能可以说是它这重要的指标。当然硬件层面的资源也是必须的。
架构
下面是项目的总体架构,第一个版本基于此方案来做。
上面的web层包括:控制台、基本权限、监控展示等,还可以根据需要再一步进行扩展。
核心层由控制者统一调度,将任务发给工人队列中的工人进行爬取操作。各个结点动态的向监控模块发送模块状态等信息,统一由展示层展示。













