

我们看到在执行计划的 Extra 信息中有信息显示“Using index for group-by”,实际上这就是告诉我们,MySQL Query Optimizer 通过使用松散索引扫描来实现了我们所需要的 GROUP BY 操作。
下面这张图片描绘了扫描过程的大概实现:
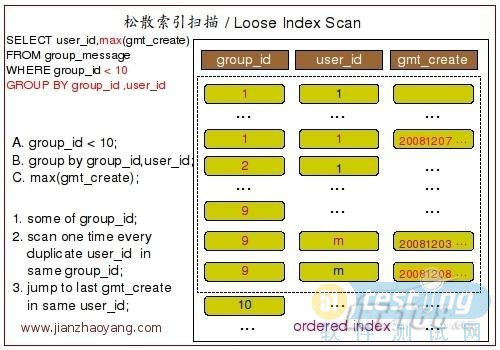
要利用到松散索引扫描实现 GROUP BY,需要至少满足以下几个条件:
◆GROUP BY 条件字段必须在同一个索引中最前面的连续位置;
◆在使用GROUP BY 的同时,只能使用 MAX 和 MIN 这两个聚合函数;
◆如果引用到了该索引中 GROUP BY 条件之外的字段条件的时候,必须以常量形式存在;
为什么松散索引扫描的效率会很高?
因为在没有WHERE子句,也就是必须经过全索引扫描的时候, 松散索引扫描需要读取的键值数量与分组的组数量一样多,也就是说比实际存在的键值数目要少很多。而在WHERE子句包含范围判断式或者等值表达式的时候, 松散索引扫描查找满足范围条件的每个组的第1个关键字,并且再次读取尽可能最少数量的关键字。
2、使用紧凑(Tight)索引扫描实现 GROUP BY
紧凑索引扫描实现 GROUP BY 和松散索引扫描的区别主要在于他需要在扫描索引的时候,读取所有满足条件的索引键,然后再根据读取恶的数据来完成 GROUP BY 操作得到相应结果。
|












