

数据库高可用架构对于我们这些应用端开发的人来说是一个比较陌生的领域,是在具体的数据库产品之上搭建的环境,需要像DBA这样对数据库产品有足够的了解才能有所涉及,虽然不能深入其中,但可以通过一些经典的高可用架构学习其中的思想。就我所了解到的有以下几种:
◆MySQL Replication
◆MySQL Cluster
◆Oracle RAC
◆IBM HACMP
◆Oracle ASM
MySQL Replication
MySQL Replication就是通过异步复制多个copy以达到提高可用性的目的,常规的复制架构有以下几种:
◆Master-Slaves
◆Master-Master
◆Master-Master-Salves
1)Master-Slaves
Master-Slaves是最常用的提高可用的方法,特别是在互联网应用中,读远远大于写,因此提高读的可用性是首当其中的,Master- Slaves就是让写的操作集中在一台数据库Master上,然后这个Master会把更新的操作复制到其他数据库Slaves上,读的操作都发生在 Slaves上,架构图如下所示:
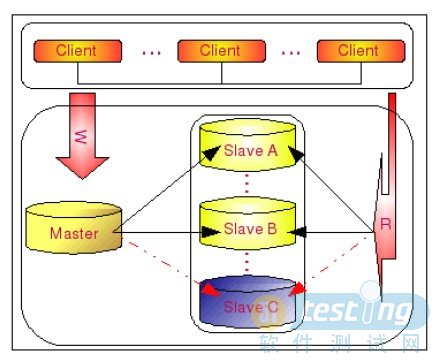
如上图在SlaveC不可用时,读和写都不会中断,等SlaveC恢复后会自动同步丢失的数据,又能重新投入运转,可维护性非常好。但如果 Master有问题就麻烦了,因此它只解决了读的高可用性,但不保证写的高可用性。关于Master-Slaves的实战可参考以前的一篇博文构建高性能web之路------mysql读写分离实战
2)Master-Master
为解决上面谈的写的高可用性,MySQL提供了Master-Master的复制架构,如下所示:

一般说来都向MasterA写,MasterA同步数据到MasterB,当MasterA有问题时,会自动切换到MasterB,等MasterA恢复时,MasterB同步数据到MasterA












