我们前面说了很多ET怎么去测试的方法,ET(探索性测试)只是一种方法,是相对于ST(基于脚本的测试)而言的,我们知道ST方法里面有个很重要的技术就是测试设计技术,使用到很多测试设计方法,比如使用等价类分析,边界值分析,因果图分析,判定表等等。这些测试设计方法可以在一定程度上可以保证测试的覆盖率。那ET要与ST去比较,也当然也有自己的测试方法去覆盖一些潜在的问题。下面将说说这些测试方法是如何应用在ET测试执行过程中。是如何让一个测试人员在一个完整的产品中实行ET测试的。
之前也说了ET和ST的关系,在一个项目实际测试过程中,是如何应用ST和ET的测试模型,不同的模型中怎么来做ET,也就是ET中的测试方法也有不同。但其核心方法是一样的,如何快速的在ET测试中使用多种测试手段,如何根据产品的反馈快速的进行下一个用例的设计和执行,这些方法是通用的。为了让大家能够更好的理解一个优秀的ET测试人员是怎么对自己需要测试的模块进行测试的,其测试思路的变化是怎么形成的,特别举几个例子来详细说明下。
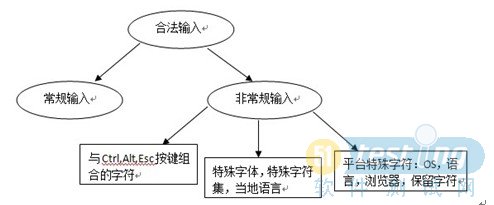
首先需要说明的是,这个快速测试的方法是基于如下一个观点:我们把测试工作简化为先在所有输入(或运行环境等)的全体集合中选择一个子集,然后在输入时使用选中的子集,最后通过推理认定是否这些输入已经足够多了。由于输入是无限多的,我们唯一的希望就寄托在正确决定我们需要变动的输入上。如果我们选择了正确的输入,就会发现有效的bug,产品质量也就会提高。基于这些理解,这边整合了一些关于输入的测试方法,怎么在输入和输出之间发挥出好的效果,怎么更好的理解输入在测试中的作用。
请看如下的“联想输入”(LI)模型分类:

原子输入:简单不能再简单的输入,属于单个的事件,比如单击按钮,输入整数4等
抽象输入:将有些相互关联的原子输入合并在一起输入,就成了抽象输入,比如输入正整数,这里面包含了原子输入4或256或2048或32768等

输入筛选器:用于防止非法的输入值被传递给应用软件的功能代码,不会产生错误信息
输入检查:属于功能代码的一部分,类似IF,ELSE语句来实现,产生特定的错误信息
异常处理代码:把整个例程(routine)当一个整体进行异常处理并产生通用的出错信息