

我们知道,数据是信息的载体——一种我们约定了如何解释的符号。在计算机系统中,最常见的应该是文本数据。我们用它记录配置信息,写日志,等等。而在应用程序中,按一定的数据结构来组织数据的方式叫做数据库管理系统(DBMS)。数据库就是把数据按照一定的规则,有效的组织存放,以提供更高效、更便捷的数据访问和处理。要理解数据库原理,并使用数据库,需要理解三点内容:1>数据库的数据组织的方式;2>数据库的逻辑架构及物理实现;3>数据库客户端的操作方法。也许,对于使用数据库来说,只需要掌握最后一点,即操作方法就可以了。但是,一个只能掌握具体操作,而无法理解领会为何要这么操作,及这些操作是为何操作的人,不过是个熟练的技术工。因为具体的操作,是一项技能,是“术”的层面的东西;而原理是“道”的层面的东西。一门技术,可能兴盛,也可能被淘汰,但原理是不会过时和被淘汰的。比如,8086处理器的指令,可以多数已经过时了,但是它的设计思想,确实永远不会过时的。
先说说数据库的数据结构。我们日常所用的文本文件,是按字节顺序存储的。要找到一个文本中的某些特定的信息,必须通过文本流的方式,从头到尾一字节一字节的将文本扫描。这种效率,平时写写脚本,理解练习I/O原理是可以的。但实际应用中,显然是不现实的。比如腾讯的几亿人的QQ号的数据,要是使用纯文本来存储,每个人登录时,岂不是都要将整个文件扫描一次?
在数据库中,用到的数据结构是——B-Tree。要了解B-Tree,我们先来了解一些二叉查找树(Binary Search Tree)。二叉查找树是一种查找高效的数据结构。二叉查找树有三个特点:1>每个节点最多只有两个子树;2>左子树的值总是小于父节点,右子树的值总是大于父节点;3>在二叉查找树中找到一个数据,平均只需要logN次比较。
二叉查找树图例
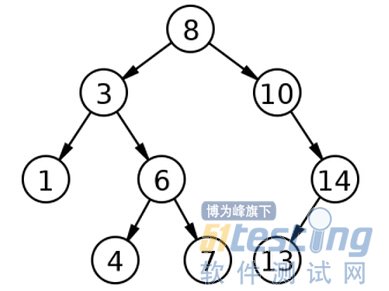
图1——二叉查找树
但是二叉查找树因为每一层最多只能有两个节点,大量的数据存放会导致层次太深。而数据的实际存放是通过文件系统存储在硬盘上的。我们知道,硬盘这个I/O外设的访问速度和内存的速度比起来,差的可是N多数量级啊。所以,访问硬盘的次数越少越好。而二叉查找树的过深的层次结构导致访问硬盘的次数剧增。所以,才有了B-Tree这个数据结构,用以组织数据库中的数据。B-Tree也有三个特点:1>一个节点可以容纳多个值;2>除非本层数据已经填满,否则不会开辟新的层;3>子节点中的值,与父节点中的值,有严格的大小对应关系。如下图:
B-Tree 图例
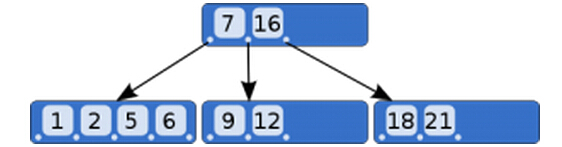
图2——B-Tree
因此,当使用B-Tree时,只需要2层就可以实现1万的数据存储。而使用二叉查找树则需要10层。同时,B-Tree具备二叉查找树的高效查找特性。当进行查找操作时,使用B树只需2次读取硬盘进行比较就可以了。而使用二叉查找树则需要10次读取硬盘进行比较。所以,B树的效率更高。
说了数据库的数据结构,在说说后面两个内容。以用得比较广泛的LAMP开源轻架构中的MySQL为例,说说MySQL的逻辑结构。MySQL由Client和Server构成,是典型的C/S架构。1>在实际应用中,充当Client通常是第三方应用(Python, PHP, Perl等)中的MySQL驱动。2>与Client通信的部分叫做连接池(connection pool),主要负责“Client”与Server的连接以及验证等。以本地socket通信和TCP/IP通信实现连接与验证。3>然后是核心层,负责提供SQL接口和查询缓存,以及查询的优化和部分内部函数的执行。4>再后是存储引擎层,真正负责数据的存储和提取。有多种存储引擎,提供不同的功能。5>最后是数据存储层,真正把数据存储在文件系统中。













