

ЎЎЎЎҪвҫцұаТлІоТмәНЖҪМЁІоТм
ЎЎЎЎҝзЖҪМЁөҘФӘІвКФЈ¬АэИзФЪPCЙПІвКФЗ¶ИлКҪПоДҝЈ¬»тФЪwindowsЙПІвКФLinuxПоДҝЈ¬УЙУЪұаТл»·ҫіҝЙДЬІ»Н¬Ј¬ҙъВлЦРНЁіЈ»біцПЦТ»Р©·ЗұкЧјөДМШКв№ШјьЧЦЈ¬ТФј°КэҫЭіӨ¶ИҝЙДЬІ»Н¬ЎЈХвР©ІоТмҝЙТФУГ№ӨҫЯЧФ¶ҜҪвҫцЎЈ
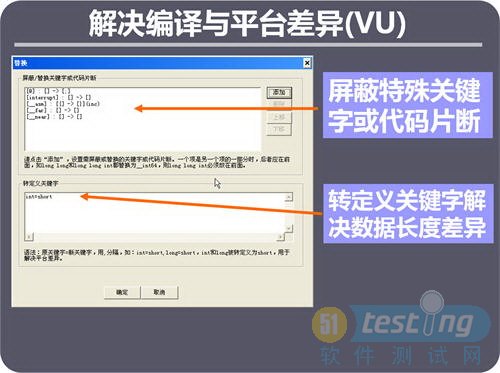
ЎЎЎЎЙПНјКЗҪвҫцұаТлІоТмәНЖҪМЁІоТмөДКҫТвҪзГжЎЈ№ӨҫЯҝЙТФЧФ¶ҜЖБұОМШКв№ШјьЧЦ»тҙъВлЖ¬¶П,ТІҝЙТФЧӘ¶ЁТе№ШјьЧЦАҙҪвҫцКэҫЭіӨ¶ИІоТмЎЈХвСщЈ¬ФЪІ»РЮёДІъЖ·ҙъВлөДЗ°МбПВЈ¬ҝЙТФұИҪПұгАыөШҪвҫцұаТлІоТмәНЖҪМЁІоТмЎЈ
ЎЎЎЎЎ°ҝЙұаіМөДЧ®ЎұІ»ДЬҪвҫцДЪІҝКдИл
ЎЎЎЎТІРнәЬ¶аИЛ¶ј»бИПОӘЈ¬ұаРҙЧ®ҙъВлҝЙТФҪвҫцДЪІҝКдИлОКМвЈ¬ДЪІҝКдИлУРБщЦЦЗйРОЈ¬ОТГЗАҙҫЯМе·ЦОцТ»ПВЎЈ
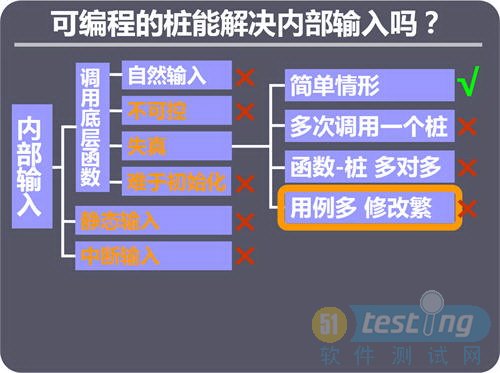
ЎЎЎЎЧФИ»КдИлЈәЧФИ»КдИлөчУГКөјКҙъВлЈ¬КЗІ»РиТӘМШұрҪвҫцөДЈ¬ёъЧ®ОЮ№ШЎЈ
ЎЎЎЎІ»ҝЙҝШЈәІ»ҝЙҝШөчУГөДТІКЗКөјКҙъВлЈ¬І»КЗөчУГЧ®ҙъВлЈ¬ТтҙЛТІІ»ДЬҪвҫцЎЈТІРнУРИЛ»бОКЈ¬БнНвұаРҙЧ®ҙъВлАҙҙъМжКөјКҙъВлРРІ»РРЈҝФЪУҰёГөчУГКөјКҙъВлөДКұәтЈ¬ТӘПлөчУГЧ®ҙъВлҝЙДЬКЗәЬВй·іөДЈ¬АэИзЈ¬өЧІгәҜКэО»УЪН¬Т»ёцОДјюЈ¬»тН¬Т»ёцАаЈ¬ИзәОИҘөчУГЧ®Јҝ
ЎЎЎЎДСУЪіхКј»ҜЈәТІКЗөчУГКөјКҙъВлЎЈ
ЎЎЎЎҫІМ¬КдИлЈәҫІМ¬КдИлЦ»Йжј°өҪҫЦІҝҫІМ¬ұдБҝЈ¬Г»УРөчУГөЧІгәҜКэЈ¬өұИ»ТІІ»ДЬУГЧ®АҙҙъМжЎЈ
ЎЎЎЎЦР¶ПКдИлЈәЦР¶ПКдИлФЪІ»И·¶ЁО»ЦГЈ¬ЦР¶ПөчУГІ»И·¶ЁөДҙъВлЈ¬ТІІ»ДЬУГЧ®АҙҙъМжЎЈ
ЎЎЎЎК§ХжЈәК§ХжКЗҙтЧ®ФміЙөДЈ¬өчУГөДКЗЧ®ҙъВлЎЈұаРҙЧ®ҙъВлҝЙТФҪвҫцТ»Іҝ·ЦК§ХжЈ¬ОТГЗАҙҫЯМе·ЦОцТ»ПВЎЈФЪұИҪПјтөҘөДЗйРОПВЈ¬ҝЙТФУГГьГы·ЁАҙҝШЦЖЧ®ҙъВлөДКдіцЈ¬јҙёшГҝёцУГАэГьГыЈ¬Ч®ҙъВлЦРЕР¶ПУГАэГыАҙҫц¶ЁКдіцЈ¬VU2.0ЧоіхөДЙијЖҫНКЗІЙУГХвЦЦ·Ҫ·ЁЈ¬ө«КЗҫӯ№эУҰУГЈ¬
ЎЎЎЎ·ўПЦЦ»ДЬҪвҫцјтөҘЗйРОЈ¬ЛщТФ·ЕЖъБЛЎЈИз№ыФЪН¬Т»ёцУГАэЦРЈ¬¶аҙОөчУГН¬Т»ёцЧ®Ј¬ГҝҙОТӘЗуКдіцІ»Н¬Ј¬ГьГы·ЁҫНОЮР§БЛЎЈХвЦЦЗйРОКЗәЬіЈјыөДЈ¬АэИзФЪСӯ»·ЦРөчУГЧ®ҙъВлЎЈТ»ёцұ»ІвәҜКэҝЙДЬөчУГ¶аёцЧ®Ј¬Т»ёцЧ®УЦҝЙДЬұ»¶аёцұ»ІвәҜКэөчУГЈ¬ХвЦЦ¶а¶Ф¶аөД№ШПөПВЈ¬әЬДСО¬»ӨУГАэУлЧ®өД¶ФУҰЎЈУГАэҝЙДЬәЬ¶аЈ¬»№ҝЙДЬТӘІ»¶ПФцјУәНРЮёДЈ¬О¬»ӨУГАэУлЧ®КдіцөД№ШПөТІәЬВй·іЎЈ












