


在上面的响应图中,每个红点都代表一个用户活动(在这里是页面请求),水平轴是时间,以秒为单位, 从测试开始时计算,垂直轴列出了每个虚拟用户。这个响应图是一个典型的“条纹式”(Striping)请求,这必须在负载测试中尽量避免的。上图是一个压力测试的好例子,但非负载测试。如果你拿一个尺子垂直地放在图上并从左到右缓慢移动,在垂直方向上,你会看到这些代表了用户活动的红点几乎是在同一线上,这也表示了服务器在同一时间接受到的用户请求。这是对实际用户群的非常差的刻划。现在看看图3。
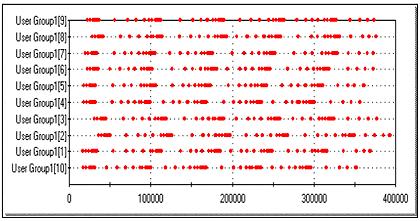
图3 非条纹式的响应图
如果你同样地用尺子来量一量,你会发现这次红点分布得更加均匀一些。虽然还不完善,但明显地更加贴近实际用户的情况。这两个测试运行唯一的区别是后者有了一定的随机延迟,而不是绝对的延迟。
在对上面的两个例子进行有计划地调整之前,有3点信息是必须知道的。在第一个例子中,我只是使用了脚本录制时的平均延迟时间。第二个中,我加入了最小和最大的延迟值以及分布。有很多这种分布的数学模型,我将重点介绍最常用的两个:均匀分布(uniform distributions)和正态分布(normal distributions),为了完整起见同样介绍了负指数分布。这个分布并不经常用到但也不是没用,高级程序员可以将这种分布和其它数学函数结合起来进行某些用户模式的模拟。
介于最小值和最大值之间的平均分布是最容易模拟的。这种分布模型只是简单的从上下边界中选择随机的数字并构成均匀分布,这意味着生成的数据并不会只在数据范围的中间或两边。图4显示了1000个0到25之间的平均分布情况。
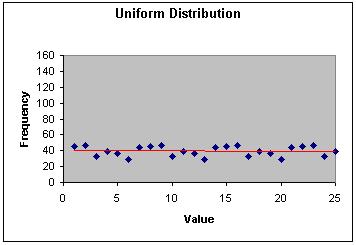
图4 最大和最小值之间的均匀分布
正态分布,也称为贝尔曲线,更难以模拟但也更加准确。这种分布模型随机地选择数字,并通过对中心值或平均值的选择频率进行相应的加权。图5展示了在0到25之间产生的1000个数字的正态分布情况(平均值为12.5,标准差为3.2)。在没有可用的实际数据的情况下,正态分布一般都被认为是最准确的数学模型。
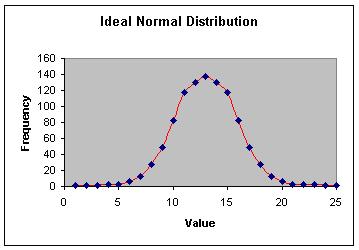
图5 理想的正态分布
负指数模型的分布情况如图6所示,这种模型延迟时间的频率明显地向末端歪斜。我觉得这种分布很少有用,但出于完整性考虑这里还是包括进来了。图6显示了在0到25之间产生1000个数字的负指数分布情况。
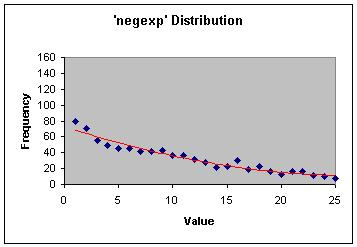
图6 负指数分布











