

摘 要:内存访问延迟是嵌入式系统性能提高的瓶颈。本文以数据在内存的存储方式为出发点来解决内存访问延迟的问题,并用遗传算法实现了优化算法。
针对有内存管理单元(MMU)的处理器设计的一些桌面操作系统(如Windows、Linux)都使用了虚拟存储器的概念,虚拟内存地址被送到MMU。在这里,虚拟地址被映射为物理地址,实际存储器被分割为相同大小的页面,采用分页的方式载入进程。一个程序在运行之前,没有必要全部装入内存,而是仅将那些当前要运行的部分页面装入内存运行。大多数嵌入式系统是针对没有MMU的处理器设计的,因此不能使用处理器的虚拟内存管理技术,而采用实存储管理策略,从而对内存的访问是直接的。它对地址的访问不需要经过MMU,而是直接送到地址线上输出,所有程序中访问的地址都是实际的物理地址。而且,大多数嵌入式操作系统对内存没有保护,各个进程实际上共享一个运行空间。一个进程在执行前,系统必须为它分配足够的连续地址空间,然后全部载入主存储的连续空间。从编译内核开始,开发人员必须告诉系统,这块开发板到底拥有多少内存;在开发程序时,必须考虑内存的分配情况并关注应用程序需要运行空间的大小。另外,由于采用实存储器管理策略,用户程序同内核以及其他用户程序在一个地址空间,程序开发时要保证不侵犯其他应用程序的地址空间,不破坏系统的正常工作,使程序正常运行。因而对内存操作要格外小心。由此可见,开发者不得不参与系统的内存管理,否则系统的效率和性能都不能令人满意。开发者可以用一个内存管理器来帮助管理内存,可以借鉴流行操作系统对内存池(pool)中块(block)进行管理的思想。访问时先寻找对应的块,然后对物理地址进行页的解码,进而是行解码,最后是列解码和根据图像处理系统处理大量数据的特点,对数据在内存中的布局进行规划。即同一块中使连续访问的数据在同一页;在同一页的数据,尽量安排在同一行,减小内存访问延迟,以便对性能进行改善。同时,内存块间相对位置也用同样的方法进行规划,使得块间的转换也尽快完成。本文采用遗传算法,同时对内存数据存储进行页、行、列的规划,对块间相对位置也进行了规划。
1 内存规划
流行的操作系统对内存访问的基本方式是支持快速缓存,执行的过程是把要访问的地址整行拷贝到缓存区,先进行页解码和行解码,然后进行列解码并根据读写信号进行选择。目前嵌入式系统中使用的DRAMs都支持高效内存访问模式,还特别支持流行的页(page)访问模式和区间(burst)访问模式(相当于以列为主的访问)。这种访问模式消耗的能量低于随机访问方式,例如,IBM′s Cu-11 Embedded DRAM macro支持的随机访问时间是10ns,而块中页访问的时间是5ns,电流分别是60mA/MB和13mA/MB。所以,充分利用内存访问模式的特点可以改变嵌入式系统的性能。
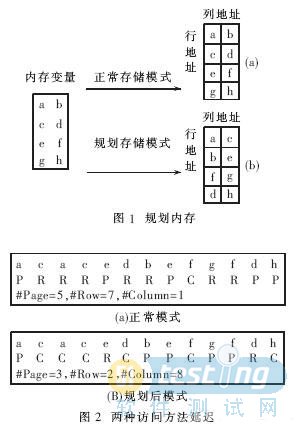
为了说明本文的规划思想,假设内存中有如图1所示的变量a,b,c,d,e,f,g,h。若要访问内存中变量的次序为acacebdbefgfdah,则根据图1中内存存放的次序,可以计算出访问延迟的时间。如果页间访问延迟时间是5个时钟周期,记为Delay(P)=5cycles,则在同页中行间访问延迟Delay(R)=3cycles,同行中列间访问延迟Delay(C)=1cycles。根据图1(a)和图1(b)中两种存储模式,可以分别计算出如图2所示的两种内存存储方式下内存访问延迟时间:Latency(a)=47cycles,Latency(b)=29cycles。
同样,将相互访问频率较高的内存块,如三个数组A、B、C分别存放在不同的内存块,数组A和数组C是经常要进行元素间计算的,则把分别存储A和C的块放在相邻的位置上,这样,既可以减小地址总线的负担,也可以提高访问时间和减少访问次数。
2 规划算法
使系统内存访问延迟最小的内存规划应该从变量和要申请的内存块在内存中存储的相对位置的角度来寻找。其前提条件是变量和内存块的访问顺序已知,申请的块的信息也可以得到。根据嵌入式系统应用的特点,例如图像处理系统,经过对程序的预处理,这个条件可以满足。处理过程可分为二步:第一步进行块间的规划;第二步对块内变量进行规划。问题的描述如下。
在嵌入式系统中,设内存块大小为S,某段时间内内存块个数为T,块中每页的大小为p*q*w,其中p为行数,q为列数,w为每个字的位数。在某个应用中有N个变量{ni,i=1,……,N},已知变量被访问的次序为njnknl……nm,则首先寻找块存储的相对位置,使得内存访问延迟函数Latency1最小(假设两个块相邻,访问需要1个时钟周期;相隔1个块,访问需要2个时钟周期;第i个块和第j个块间访问需要i-j个时钟访问延迟):
Latency1={Sum|∑z*(i-j)/z,z=1....m} (1)
其中:z是访问顺序表中内存块的位置,如第3个位置(z=3)访问的是bi,下一个位置存放的是bj,i和j是内存块访问顺序中相邻块标号,是块在内存中存储的相对位置,m是访问内存块的顺序排列长度。其次寻找N个变量在内存块内的存储相对位置的一种规划{nxnynz……nt},使得内存访问延迟函数Latency2最小,块内规划目标函数为:
Min:Latency2=5*#P+3*#R+#C (2)
其中:#P是规划中访问的页间转换的次数,#R是行间转换的次数,#C是列间转换的次数。N个变量的排列方法的数目共有N!种,要在如此多的情况下寻找某种最优的排列,这是NP问题。解决这类优化问题有很多方法,如模拟退火算法、演化算法等一些启发算法,也可以用曲线图划分问题(graph partitioning problem)的方法来解决此问题。本文采用了最近几年发展很快的遗传算法来解决此规划问题。遗传算法是解决NP问题的有效方法。本文的研究目的在于内存规划的意义,而不是遗传算法,所以采用经典遗传算法[8],以此来验证内存规划的有效性。本文的算法可记为LBP(LBP-Layout of Block and Page)。












