

ЎЎЎЎјаКУ
ЎЎЎЎФЪЙъіЙєПАнµДУГ»§ёєФШєуЈ¬јаКУ№¤ѕЯРиТЄКХјЇЅшіМµДФЛРРЧґїцЎЈФЪОТµДІвКФ»·ѕіЦРїЙТФКХјЇµЅёчЦЦУРУГµДРЕПўЈє
ЎЎЎЎ1ЎўЛщУРјЖЛг»ъЎўНшВзЙи±ёµИµИµДК№УГВК
ЎЎЎЎ2ЎўJVMµДНіјЖКэѕЭЎЈ
ЎЎЎЎ3Ўўёц±рJAVA·Ѕ·ЁЛщ»Ё·СµДК±јдЎЈ
ЎЎЎЎ4ЎўКэѕЭївРФДЬРЕПўЈ¬°ьАЁSQLІйСЇµДНіјЖЎЈ
ЎЎЎЎ5ЎўЖдЛыУ¦УГПа№ШµДРЕПўЎЈ
ЎЎЎЎµ±И»ХвР©јаКУТІ»бУ°ПмёєФШІвКФЈ¬µ«Из№ыУ°Пм±ИЅПРЎТІїЙТФєцВФЎЈ»щ±ѕЙПИз№ыОТГЗПл»сИЎЛщУРЙПГжµДРЕПўЈ¬їП¶Ё»бУ°ПмІвКФµДРФДЬЎЈµ«Из№ыІ»КЗТ»ґО»сИЎЛщУРРЕПў»№КЗУРїЙДЬ±ЈЦ¤ёєФШІвКФµДУРР§РФЎЈЅц¶ФМШ¶ЁµД·Ѕ·ЁЙиЦГ¶ЁК±ЖчЈ¬Ѕц»сИЎµНёєФШµДУІјюРЕПўєНµНЖµВКµШ»сИЎСщАэКэѕЭЎЈµ±И»І»јУФШјаКУЖчАґЧцІвКФКЗЧоєГµДЈ¬И»єуєНјУФШјаКУЖчµДІвКФАґЧц±ИЅПЎЈЛдИ»УРК±єтЗЦИлКЅјаКУКЗёцєГЦчТвЈ¬µ«ѕНІ»їЙДЬУРјаКУЅб№ыБЛЎЈ
ЎЎЎЎ»сИЎЛщУРјаКУКэѕЭµЅТ»ёцЦРСлїШЦЖЖчАґЧц·ЦОцКЗЧоєГµДЈ¬µ«К№УГ¶ЇМ¬ФЛРРК±№¤ѕЯТІїЙТФМṩУРУГµДРЕПўЎЈАэИзЈ¬ГьБоРР№¤ѕЯИзPSЎўTOPЎўVMSTATїЙТФМṩUNIX»ъЖчµДРЕПўЈ»РФДЬјаКУЖч№¤ѕЯїЙТФМṩWINDOWS»ъЖчµДРЕПўЈ»¶шTeamQuestЈ¬ BMC PatrolЈ¬ SGI's Performance Co-PilotЈ¬ and ISM's PerfManХвСщµД№¤ѕЯ»бФЪЛщУРµДІвКФ»·ѕіЦРµД»ъЖч°ІЧ°ґъАнІўЗТЅ«РиТЄµДРЕПўґ«»ШЦРСлїШЦЖ»ъЈ¬ХвСщѕНїЙТФМṩОД±ѕ»тїЙКУ»ЇµДРЕПўЎЈФЪ±ѕОДЦРЈ¬ОТК№УГїЄФґµДPerformance Co-PilotЧчОЄІвКФНіјЖµД№¤ѕЯЎЈОТ·ўПЦЛы¶ФІвКФ»·ѕіµДУ°ПмЧоРЎЈ¬ІўЗТТФПа¶ФЦ±ЅУµД·ЅКЅАґМṩКэѕЭЎЈ
ЎЎЎЎJAVA·ЦОцЖчМṩєЬ¶аРЕПўЈ¬µ«НЁіЈ¶ФёєФШІвКФАґЛµУ°ПмМ«ґу¶шГ»УРМ«¶аµДУГґ¦ЎЈ№¤ѕЯЙхЦБїЙТФИГДгФЪёєФШ·юОсЖчЙПЧцТ»Р©·ЦОцЈ¬µ«ХвТІєЬИЭТЧ±гІвКФОЮР§ЎЈФЪХвР©ІвКФЦРЈ¬ОТј¤»оБЛПкПёµДА¬»шКХјЇЖчАґКХјЇДЪґжРЕПўЎЈОТТІК№УГjconsole єНjstack№¤ѕЯЈЁ°ьє¬ФЪJ2SE 1.5ЦРЈ©АґјмІйёЯёєФШПВµДVMЎЈОТГ»УР±ЈБфХвР©ІвКФУГАэЦРёєФШІвКФµДЅб№ыТтОЄОТИПОЄХвР©КэѕЭІ»КЗєЬХэИ·ЎЈ
ЎЎЎЎН¬ІЅЖїѕ±
ЎЎЎЎФЪХп¶П·юОсЖчОКМвК±ПЯіМµДРЕПўКЗ·ЗіЈУРУГµДЈ¬МШ±рКЗ¶ФН¬ІЅЦ®АаµДОКМвЎЈjstack№¤ѕЯїЙТФБ¬ЅУµЅФЛРРµДЅшіМІўЗТ±ЈґжГїТ»ёцПЯіМµД¶СХ»РЕПўЎЈФЪUNIXПµНіїЙТФУГРЕєЕБї3Аґ±ЈґжПЯіМµД¶СХ»РЕПўЈ¬ФЪWINDOWSПµНіµДїШЦЖМЁЦРїЙТФУГCtrl-BreakЎЈФЪµЪТ»ПоІвКФЦРЈ¬jstackЦёіцРн¶аПЯіМФЪgrindCPU()·Ѕ·ЁЦР±»ЧиИыЎЈ
ЎЎЎЎДгїЙТФТСѕЧўТвµЅБР±н2ЦРgrindCPU()·Ѕ·ЁµДН¬ІЅРЮКО·ыКµјКЙПІўІ»±ШРлЎЈОТФЪєуТ»ПоІвКФЦРЙѕіэБЛЛыЈ¬ИзНј2ПФКѕ

Figure 2
ЎЎЎЎФЪНј2ЦРЈ¬Дг»бЧўТвµЅРФДЬПВЅµБЛЎЈЛдИ»ОТК№УГБЛёь¶аµДCPUЈ¬µ«НМНВБїєНК§°ЬКэ¶јёьІоБЛЎЈЛдИ»А¬»ш»ШКХЦЬЖЪ±дБЛЈ¬µ«ГїГлТАИ»РиТЄ»ШКХ100MЎЈПФИ»ОТГЗ»№Г»УРХТµЅЦчТЄµДЖїѕ±ЎЈ
ЎЎЎЎ·Зѕ№ХщµДН¬ІЅПа¶ФУЪјтµҐµДєЇКэµчУГ»№КЗєЬ·СК±µДЎЈѕ№ХщРФµДН¬ІЅѕНёь·СК±БЛЈ¬ТтОЄіэБЛДЪґжРиТЄН¬ІЅНвЈ¬VM»№РиТЄО¬»¤µИґэµДПЯіМЎЈФЪХвЦЦЧґїцПВЈ¬ХвР©ґъјЫКµјКЙПТЄРЎУЪДЪґжЖїѕ±ЎЈКµјКЙПЈ¬НЁ№эПыіэБЛН¬ІЅЖїѕ±Ј¬VMДЪґжПµНііРµЈБЛёь¶аµДС№Б¦ЧоєуµјЦВёьІоµДНМНВБїЈ¬јґК№ОТК№УГБЛёь¶аµДCPUЎЈПФИ»ЧоєГµД·ЅКЅКЗґУЧоґуµДЖїѕ±їЄКјЈ¬µ«УРК±ХвТІІ»КЗєЬИЭТЧИ·¶ЁµДЎЈµ±И»Ј¬И·±ЈVMµДДڴ洦АнЧг№»ХэіЈТІКЗТ»ёцєГµДїЄКј·ЅПтЎЈ
ЎЎЎЎДЪґжЖїѕ±
ЎЎЎЎПЦФЪОТ»бКЧПИТІ¶ЁО»ДЪґжОКМвЎЈБР±н3КЗGrinderServletµДЦШ№№°ж±ѕЈ¬К№УГБЛStringBufferКµАэЎЈНј3ПФКѕБЛІвКФЅб№ыЎЈ
ЎЎЎЎListing 3
ЎЎЎЎpackage pub.capart; |
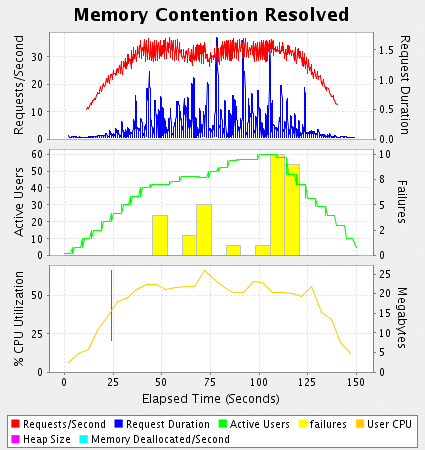
Figure 3
ЎЎЎЎНЁіЈЦШУГStringBufferІўІ»КЗТ»ёцєГЦчТвЈ¬µ«ХвАпОТЦ»КЗОЄБЛЦШПЦТ»Р©іЈјыµДОКМвЈ¬¶шІ»БїМṩЅвѕц·Ѕ°ёЎЈДЪґжКэѕЭТСѕґУНјЙППыК§БЛТтОЄІвКФЦРГ»УРА¬»ш»ШКХЖчФЛРРЎЈНМНВБїП·ѕзРФµДФцјУ¶шCPUК№УГВКУЦ»ШµЅБЛ50%ЎЈБР±н3І»Ц»КЗУЕ»ЇБЛДЪґжЈ¬µ«ОТИПОЄЦчТЄБЛёДЙЖБЛ№э¶ИµДДЪґжПыєДЎЈ












