

ЎЎЎЎЛСЛчТэЗжЛчТэөДөИёЕВКЛж»ъІЙСщЈә
ЎЎЎЎ¶ФУЪЛСЛчТэЗжөИёЕВКЛж»ъІЙСщөДСРҫҝТСҫӯУРБЛПаөұіӨөДАъК·Ј¬ҫЯМеөДұіҫ°ОДПЧОТГЗІ»ЧјұёФЪХвАпТ»Т»МҪМЦЎЈОТГЗПЈНыНЁ№э¶ФBar-YossefөИИЛЧоҪь№ӨЧчөДҪйЙЬЈ¬°СТ»ЦЦұИҪПҝН№ЫЎўҝЖС§өДІвКФ·Ҫ·ЁНЖҪйёш¶БХЯЎЈОТГЗТІ»бМҪМЦЛыГЗөД·Ҫ·Ё¶ФУЪЦРОДЛчТэөДҫЦПЮРФәНТ»Р©Ҫвҫц·Ҫ°ёЎЈ
ЎЎЎЎ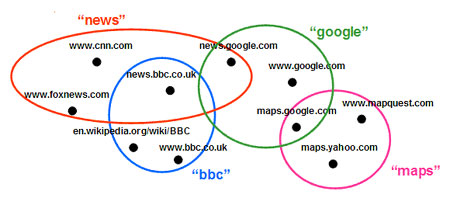
ЎЎЎЎНј3 Т»ёцјт»ҜөДЛСЛчТэЗжЛчТэ
ЎЎЎЎНј3ёшіцБЛТ»ёцјт»ҜБЛөДЛСЛчТэЗжЛчТэКҫАэЈ¬јЩ¶Ё№ШјьЧЦЎ°newsЎұҪ«·ө»Ш4ёцҪб№ыЈәwww.cnn.comЎўnews.google.comЎўwww.foxnews.comәНnews.bbc.co.ukЎЈ
ЎЎЎЎКЧПИОТГЗёшіцТ»Чй¶ЁТе
ЎЎЎЎЎс №ШјьЧЦЛСЛчҪб№ыјҜәПЈәresults(q) = { ЛСЛч№ШјьЧЦ qЛщ·ө»ШөДИ«ІҝҪб№ыОДөөЦ®јҜәП}
ЎЎЎЎЎс ОДөө№ШјьЧЦјҜәПЈәqueries(x) = { ЛщУРДЬ·ө»ШОДөөxөДЛСЛч№ШјьЧЦЦ®јҜәП}
ЎЎЎЎЎс ЛСЛч№ШјьЧЦіШPЈәТ»ЧйАнВЫЙПДЬ№»ёІёЗЛщУРОДөөөДЛСЛч№ШјьЧЦјҜәП
ЎЎЎЎo АэИзНј3ЦРP= {news, bbc, maps, google}
ЎЎЎЎЎс №ШјьЧЦЛСЛчҪб№ыБҝЈәcard(q) = |results(q)|Ј¬ЛСЛч№ШјьЧЦ qЛщ·ө»ШөДИ«ІҝҪб№ыОДөөЦ®КэБҝ
ЎЎЎЎo АэИзНј3ЦР card(Ў°newsЎұ) = 4Ј¬card(Ў°bbcЎұ) = 3
ЎЎЎЎЎс ОДөөЖҘЕд¶И:deg(x) = |queries(x)| Ј¬И«МеДЬ№»ЖҘЕдОДөөxөДЛСЛч№ШјьЧЦКэБҝ
ЎЎЎЎo АэИзНј3ЦРdeg(www.cnn.com) = 1Ј¬deg(news.bbc.co.uk) = 2
ЎЎЎЎөұОТГЗНЁ№эЛСЛчҝт¶ФЛСЛчТэЗжөДЛчТэҪшРРІЙСщЈ¬Лщ»сөГөДҪб№ыКөјКЙПЖ«ПтУЪЖҘЕд¶ИёЯөДОДөөЎЈ¶ФУЪНј3ЛщКҫөДЛСЛчТэЗжЈ¬Из№ыОТГЗҙУЛСЛч№ШјьЧЦіШP = {news, bbc, maps, google}ЦРИОТвСЎИЎТ»ёц№ШјьЧЦЈ¬И»әуФЪЛщөГЛСЛчҪб№ыЦРИОТвСЎИЎТ»ёцОДөөЈ¬ДЗГҙСЎөҪДіТ»ёцҫЯМеОДөөөДёЕВКУлЛьөДЖҘЕд¶ИіЙХэұИЈ¬АэИзЈ¬p(news.bbc.co.uk) = 2/13 Ј¬p(www.cnn.com) = 1/13
ЎЎЎЎТтҙЛЈ¬НЁ№э№ШјьЧЦ¶ФЛСЛчТэЗжөДЛчТэҪшРРІЙСщЈ¬КөјКЙПКЗ¶ФОДөөЖҘЕд¶ИёЕВК·ЦІјФЪЧчЛж»ъійСщЎЈҫЯМеөШЛөЈ¬Из№ыПа¶ФУЪТ»ёцёш¶ЁөДЛСЛч№ШјьЧЦіШPЈ¬ёГЛчТэөДИ«ІҝОДөөЖҘЕд¶ИөДЧЬәНОӘdeg(D) = ЎЖxЎКDdeg(x)Ј¬ДЗГҙНЁ№эЛСЛчҝт¶ФТэЗжІЙСщ»сИЎҫЯМеТ»ёцОДөөxөДёЕВККЗdeg(x)/ deg(D)ЎЈ
ЎЎЎЎИзәОНЁ№э¶ФОДөөЖҘЕд¶И·ЦІјөДЛж»ъійСщ¶ш»сөГОТГЗЛщЖЪНыөДөИёЕВКЛж»ъІЙСщДШЈҝХвХэКЗBar-Yossef өИИЛ№ӨЧчөДЦчТӘіЙ№ыЛщФЪЈәЛыГЗІЙУГГЙМШҝЁВЮ·ВХжЈЁMonte Carlo SimulationЈ©Лг·ЁКөПЦБЛХвТ»өг
ЎЎЎЎЎс Дҝұк·ЦІјҰР(x) :DЙПөДөИёЕВКЛж»ъ·ЦІј, ҰР(x) = 1/|D|
ЎЎЎЎЎс КөјКІЙСщ·ЦІјp(x) :DЙПөДОДөөЖҘЕд¶ИЛж»ъ·ЦІјЈ¬p(x) = deg(x) / ЎЖx'ЎКDdeg(x')
ЎЎЎЎЎс Ж«ІоИЁЦө: w(x) = ҰР(x)/p(x) ЎШ1/deg(x)
ЎЎЎЎІЙСщ№эіМЈ¬ІОјыНј4
ЎЎЎЎЎс СЎ¶ЁТ»ёцЛСЛч№ШјьЧЦіШP
ЎЎЎЎЎс Лж»ъСЎИЎq ЎКP
ЎЎЎЎЎс ФЪЛСЛчҪб№ыЦРЛж»ъСЎИЎТ»ёцОДөөx ЎКresults(q)
ЎЎЎЎЎс јЖЛгёГОДөө¶ФP өДЖҘЕд¶Иdeg(x)
ЎЎЎЎЎс ІъЙъТ»ёц0~1өДЛж»ъКэrЈ¬Из№ыr ЎЬ 1/deg(x)ұЈБфёГОДөөЈ¬·сФт·ЕЖъ
ЎЎЎЎЎс ЦШёҙЙПКц№эіМЦұөҪ»сөГNёцУРР§ІЙСщөг
ЎЎЎЎ
ЎЎЎЎНј4 НЁ№эГЙМШҝЁВЮ·ВХжЈЁMonte Carlo SimulationЈ©Лг·ЁКөПЦ¶ФЛчТэөДөИёЕВКЛж»ъІЙСщ
ЎЎЎЎОКМвәНМЦВЫ
ЎЎЎЎЙПКцЛг·ЁФЪКэС§ЙП·ЗіЈСПҪчУЕГАЈ¬ө«КЗФЪҫЯМеөДКөПЦ№эіМЦРИФИ»УРПаөұ¶аөДА§ДСЈ¬УИЖдКЗ¶ФУЪЦРОДЛСЛчТэЗжЈ¬УРТ»Р©МШКвөДОКМвРиТӘМҪМЦЎЈ
ЎЎЎЎЎс ЛСЛч№ШјьЧЦіШPөДСЎИЎ
ЎЎЎЎPСЎФсөДМхјюКЗЈЁ1Ј©ТӘұЈЦӨp(x) = 0Ј¬јҙЛчТэЦРОДөөІ»ЖҘЕдИОәОТ»ёц№ШјьЧЦq ЎКPөДёЕВКЧг№»РЎЎЈИз№ыХвёцёЕВКМ«ёЯЈ¬ІвКФЦ»ДЬҫЦПЮУЪЛчТэөДТ»РЎІҝ·ЦЈ¬ІвКФөДҪб№ыҫНК§ИҘБЛТвТеЎЈЈЁ2Ј©№ШјьЧЦЛСЛчҪб№ыБҝcard(q)ЧоәГТӘұИҪПРЎЈ¬ХвСщҝЙТФҫЎҝЙДЬөШұЬГвЛСЛчҪб№ыі¬№эЛСЛчТэЗжФКРн·ө»ШҪб№ыөДЙППЮЎЈЧчХЯМбіцөД·Ҫ°ёКЗНЁ№эЧҘИЎәН·ЦОцТ»ёцҙуРНөДНшЙПОДҝвЈ¬АэИзО¬»щ°ЩҝЖИ«КйЈ¬СЎФсЖдЦРЛщУРөДУўОДөҘҙКөДјҜәП»тХЯЛщУРKёцПаБ¬өҘҙКөДјҜәПЧчОӘPЎЈХв¶ФУЪГ»УР·ЦҙКОКМвөДУўОД¶шСФКЗИЭТЧКөПЦөДЈ¬ө«¶ФУЪәәУпөИРиТӘ·ЦҙКөДУпЦЦЈ¬Хвёц·Ҫ·ЁЛЖәхІўІ»әЬәПККЎЈОТГЗҪЁТйЦұҪУІЙУГGBKЧЦҝвЦРөДИ«ІҝЧЦ·ыЈ¬»тХЯІЙУГЦРОД·ЦҙКұкЧјЦРЛщУРҙК»гөДјҜәПЎЈ
ЎЎЎЎЎс ИзәОјЖЛгОДөө¶ФPөДЖҘЕд¶Иdeg(x)Јҝ
ЎЎЎЎОДөөЖҘЕд¶Иdeg(x)ұШРлАлПЯјЖЛгЈ¬НЁ№эІйСҜ»сөГКЗІ»ПЦКөөДЎЈ¶ФУўОДОДөөАҙЛөЈ¬Ц»ТӘјЖЛгОДөөЦРёІёЗБЛ¶аЙЩёц№ШјьЧЦq ЎКPЎЈө«КЗ¶ФЦРОД¶шСФЈ¬І»Н¬ТэЗж°ьә¬БЛІ»Н¬өДЛСЛчВЯјӯЈ¬АэИзЛДёцәәЧЦТФПВөДЛСЛчНЁіЈІЙИЎҙКЧйЛСЛчЈ¬іӨЛСЛчҙКУРР©ТэЗжҝЙДЬІЙИЎУл»тВЯјӯЎЈІ»Н¬ТэЗж¶ФУЪәәУп·ЦҙКөДҙҰАнТІУРҪПҙуөДІоТмЎЈФЪЛчТэОДөөКұЈ¬УРР©ТэЗжҝЙДЬҝјВЗБЛ·ұјтәәЧЦөДЧӘ»»ЎЈЛщУРХвР©¶ј»б¶ФЖҘЕд¶ИІъЙъТ»¶ЁіМ¶ИөДУ°ПмЎЈ
ЎЎЎЎКөјКЙПЈ¬ЖҘЕд¶Иdeg(x)өДјЖЛгІўІ»Т»¶ЁТӘК®·Цҫ«И·Ј¬Т»Р©ҪьЛЖҙҰАнКЗҝЙТФҪУКЬөДЈ¬Ц»ТӘОуІоІ»ЦБУЪМ«ҙуЎЈОТГЗҪЁТйУГGBKЧЦҝвөДөҘёцәәЧЦјҜәПЧчОӘPЈ¬ХвСщҝЙТФұЬГв·ЦҙКөДІоТмЎЈ¶шҙЛКұОДөөөДЖҘЕд¶ИҫНКЗТ»ёцОДөө°ьә¬І»Н¬GBKЧЦ·ыөДёцКэЎЈ
ЎЎЎЎЎс ЛСЛчТэЗж¶ФЛСЛчЧоҙу·ө»ШҪб№ыөДПЮЦЖЎЈ
ЎЎЎЎХвТ»өгBar-Yossef өИИЛөДОДХВЦРУРұИҪППкПёөДМЦВЫЈ¬ЛыГЗИПОӘХвёцПЮЦЖ¶ФУЪІвКФҪб№ыөДУ°ПмІўІ»М«ҙуЎЈ
ЎЎЎЎЎс ёГЛг·ЁөДјЖЛгёҙФУ¶ИұИҪПёЯЎЈ
ЎЎЎЎҙУјЖЛгБҝЙПҝјВЗЈ¬УЙУЪdeg(x)Т»°г¶јұИҪПҙуЈ¬ТтҙЛЛСЛчҪб№ыОДөөұ»·ЕЖъөДұИАэҪПёЯЈ¬ИзәОҪшТ»ІҪёДҪшЛг·ЁөДёҙФУ¶ИКЗТ»ёцЦөөГМҪМЦөДОКМвЎЈ
Па№ШФД¶БЈә
ИзәОІвКФЛСЛчТэЗжөДЛчТэБҝҙуРЎЈЁЗ°ЖӘЈ©












