

ЁЁЁЁ2ЃЎЁАResult CollectionЁБбЁЯюПЈЃЈШчЭМ2-70ЫљЪОЃЉ
ЁЁЁЁЭЈЙ§ЁАResult CollectionЁБбЁЯюПЈПЩвдХфжУ Analysis вдЩњГЩКЭЯдЪОеЊвЊЪ§ОнЛђЭъећЪ§ОнЁЃ
ЁЁЁЁ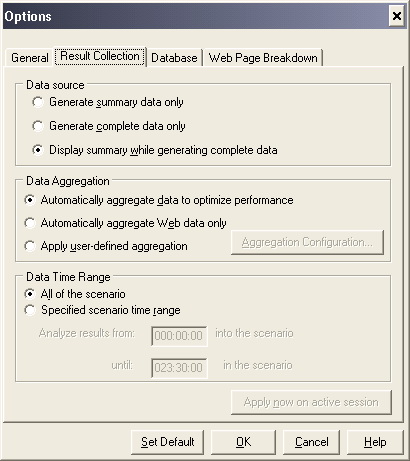
ЁЁЁЁЭМ2-70 ЁАResult SettingЁБбЁЯюПЈ
ЁЁЁЁЁАЭъећЪ§ОнЁБжИвбОЙ§ДІРэЕФПЩвддкAnalysisЙЄОпФкЪЙгУЕФНсЙћЪ§ОнЃЌПЩвдДцДЂЁЂЩИбЁКЭВйзнетаЉЪ§ОнЁЃЁАеЊвЊЪ§ОнЁБжИдЪМЕФЁЂЮДДІРэЕФЪ§ОнЁЃеЊвЊЭМАќКЌГЃЙцаХЯЂЃЈШчЪТЮёУћКЭДЮЪ§ЃЉЃЌЖјЧвжЛжЇГжВПЗжЩИбЁбЁЯюЁЃ
ЁЁЁЁдкЁАResult CollectionЁБбЁЯюПЈжаЃЌга3ЯюашвЊХфжУЃЌЗжБ№ЮЊЁАData SourceЁБЃЈЪ§ОндДЯдЪОЧщПіЃЉЁЂЁАData AggregationЁБЃЈЪ§ОнОлКЯЗНЪНЃЉКЭЁАData Time RangeЁБЃЈЩшжУЪ§ОнЪБМфЗЖЮЇЃЉЁЃ
ЁЁЁЁЯТУцЖдЁАOptionsЁБЖдЛАПђжаЕФЁАResult SettingЁБбЁЯюПЈНјааХфжУЫЕУїЃЌШчЭМ2-70ЫљЪОЁЃ
ЁЁЁЁЪзЯШЪЧбЁдёЪ§ОндДЕФЪ§ОнЯдЪОЧщПіЃЌ3ИібЁЯюЕФКЌвхЗжБ№ЮЊЃК
ЁЁЁЁЁё Generate summary data onlyЃЈНіЩњГЩеЊвЊЪ§ОнЃЉЃКНіВщПДеЊвЊЪ§ОнЃЌAnalysisВЛЛсДІРэЪ§ОнвдгУгкЩИбЁКЭЗжзщЕШИпМЖгУЭОЁЃ
ЁЁЁЁЁё Generate complete data onlyЃЈНіЩњГЩЭъећЪ§ОнЃЉЃКНіВщПДОЙ§ДІРэЕФЭъећЪ§ОнЃЌВЛЯдЪОеЊвЊЪ§ОнЁЃ
ЁЁЁЁЁё Display summary while generating complete dataЃЈЩњГЩЭъећЪ§ОнЪБЯдЪОеЊвЊЪ§ОнЃЉЃКдкДІРэЭъећЪ§ОнЕФЪБКђЃЌФмЙЛВщПДеЊвЊЪ§ОнЁЃдкДІРэЭъећЪ§ОнжЎКѓЃЌВщПДДІРэКѓЕФЭъећЪ§ОнЁЃ
ЁЁЁЁЦфДЮЪЧбЁдёЪ§ОнЕФОлКЯЗНЪНЃЌШчЙћбЁдёЩњГЩЭъећЪ§ОнЃЌAnalysisНЋЭЈЙ§ФкжУЪ§ОнОлКЯЙЋЪНЛђЖЈвхЕФОлКЯЩшжУРДОлКЯЩњГЩЕФЪ§ОнЁЃЮЊСЫМѕаЁЪ§ОнПтЃЌЫѕЖЬдкДѓЗНАИжаЕФДІРэЪБМфЃЌБиаыНјааЪ§ОнОлКЯЁЃ
ЁЁЁЁдкЁАData AggregationЁБВПЗжЕФЩшжУФЌШЯЮЊЕквЛЯюЁАAutomatically aggregate data to optimize performanceЁБЃЌЪЙгУФкжУЪ§ОнОлКЯЙЋЪНОлКЯЪ§ОнЁЂЕкЖўИібЁЯюНіЖдWebЪ§ОнНјааОлКЯЁАAutomatically aggregate Web data onlyЁБЁЂЛЙПЩвдздЖЈвхОлКЯЕФЩшжУЃЌМДбЁдёЕкШ§ИібЁЯюЁАApply user-defined aggregationЁБЃЌЕЅЛїЦфКѓУцЕФздЖЈвхХфжУАДХЅЃЌДђПЊЁАData Aggregation ConfigurationЁБЃЈЪ§ОнОлКЯХфжУЃЉЖдЛАПђЃЌНјааздЖЈвхОлКЯКЭСЃЖШЩшжУЃЌШчЭМ2-71ЫљЪОЁЃ
ЁЁЁЁдкЭМ2-71ЫљЪОЕФЖдЛАПђжаЃЌЪзЯШбЁдёвЊОлКЯЕФЪ§ОнРраЭЃЌЦфжаСаГівЊОлКЯЪ§ОнЕФЭМЕФРраЭЃЌгаЪТЮёЃЈЯьгІЪБМфЁЂУПУыЃЉЁЂWebЃЈУПУыЕуЛїДЮЪ§ЁЂЭЬЭТСПЁЂУПУывГЪ§ЁЂHTTPЗЕЛиДњТыЃЉЁЂМрЪгЦїЁЂЪ§ОнЕуКЭНХБОДэЮѓЁЃдкИїбЁЯюЧАУцЕФИДбЁПђЩЯДђЙГМДЮЊбЁжаЁЃ
ЁЁЁЁШЛКѓдйбЁдёвЊОлКЯЕФЭМЪєадЃЌАќРЈVuser IDЁЂзщУћКЭНХБОУћЃЌШчЙћВЛЯЃЭћОлКЯЪЇАмЕФVuserЪ§ОнЃЌЧыбЁдёЁАDo not aggregate failed VusersЁБЃЈВЛОлКЯЪЇАмЕФVuserЃЉЁЃ
ЁЁЁЁ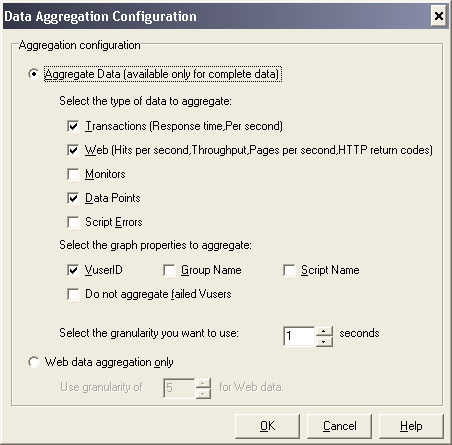
ЁЁЁЁЭМ2-71 Ъ§ОнМЏКЯХфжУЭМ
ЁЁЁЁзюКѓЖдЭМаЮЕФЯдЪОСЃЖШНјааЩшжУЃЌСЃЖШЕФЕЅЮЛЮЊУыЃЌзюаЁЕФСЃЖШЪЧ1УыЃЌзюДѓЕФСЃЖШЪЧЭМЕФЪБМфЗЖЮЇЕФвЛАыЁЃдкДЫЩшжУКѓЃЌЫцзХЭМаЮЪБМфЗЖЮЇЕФдіДѓЃЌдкЦфЫћЕиЗНПЩвдЖдСЃЖШНјааИќИФЃЌдкКѓУцЛсЖдИќИФСЃЖШЕФЗНЗЈНјааМђвЊНщЩмЁЃЛЙПЩвдбЁдёзЈУХжИЖЈWebЪ§ОнЕФздЖЈвхСЃЖШЃЌФЌШЯжЕЮЊ5УыЁЃ
ЁЁЁЁШЗЖЈКѓЃЌЕЅЛїЁАOKЁБАДХЅЙиБеЁАЪ§ОнОлКЯХфжУЁБЖдЛАПђЁЃ
ЁЁЁЁдкЁАResult SettingЁБбЁЯюПЈвГУцжазюКѓвЛЯюЁАData Time RangeЁБОЭЪЧЩшжУЪ§ОнЪБМфЗЖЮЇЃЌФЌШЯЕФЗЖЮЇЮЊЁАAll of the ScenarioЁБЃЈЫљгаЗНАИЃЉЃЌМДЯдЪОЗНАИећИіГжајЪБМфФкЕФЪ§ОнЁЃЕЅЛїЁАApply now on active sessionЁБАДХЅКѓЃЌНЋЕБЧАЩшжУгІгУЕНЕБЧАЛсЛАжаЁЃ












