测试必须在时间、质量和成本之间获取一个平衡点,这是测试策略和测试设计的价值体现。

2.18 爬页面源码(page_source)
上一篇 /
下一篇 2018-06-12 10:52:39
/ 个人分类:Python+Selenium2 WebDriver API
2.18 爬页面源码(page_source)
�w5X�@�P3r�T�V0前言
�G/D�y0N's�~�E�_0有时候通过元素的属性的查找页面上的某个元素,可能不太好找,这时候可以从源码中爬出想要的信息。selenium的page_source方法可以获取到页面源码。
�e�C3o)j�d0一、page_source
�j%z5A8C�E t6c01.selenium的page_source方法可以直接返回页面源码
�u�E�{:B�G
X;D02.重新赋值后打印出来
�V9t7d P�s�q2^
T$K�a0�]�@�k�V�j2b*A0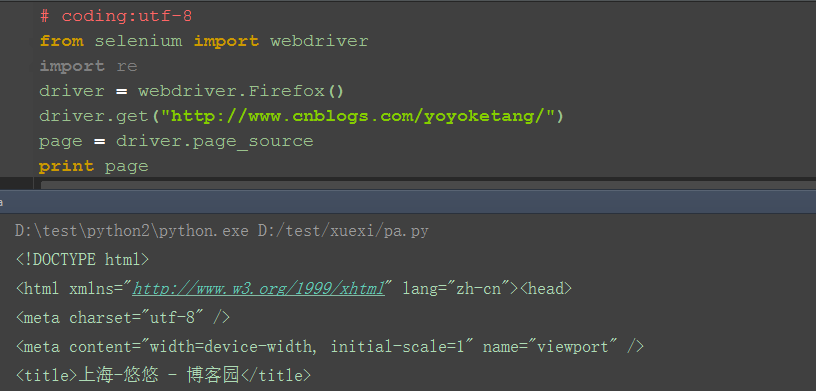
+m$[+W
a�j*]5f0 a�W�~0G
{5l(}3r�N:j�F�R+Y0二、re非贪婪模式51Testing软件测试网6k�_ c+t�N�O
F
1.这里需导入re模块(正则表达式模块)
+n'P,} ~-`�p6}�^4n�q�Q02.用re的正则匹配:非贪婪模式51Testing软件测试网�Z�i�f8J%J7`
3.findall方法返回的是一个list集合51Testing软件测试网
u9l4i�[.^%[-W�N7`
4.匹配出来之后发现有一些不是url链接,可以筛选下51Testing软件测试网�n0?6{�Q�I�I�i%?�N
�U�X�\1\*n�h�?0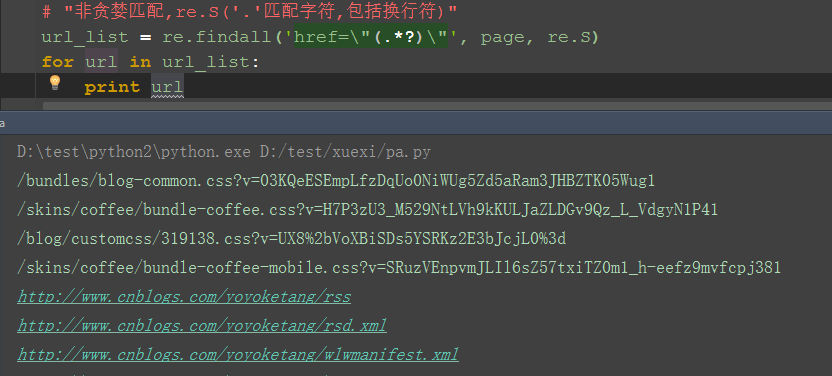 51Testing软件测试网!n�?�J2N
J
51Testing软件测试网!n�?�J2N
J
�Q�}�B�e�t2U/{0三、筛选url地址出来51Testing软件测试网:[%Q#p�w:O�^�b+s�[
1.加个if语句判断,‘http’在url里面说明是正常的url地址了
�z6O�\%m�?"_�a02.把所有的url地址放到一个集合,就是我们想要的结果啦51Testing软件测试网�e�U7I�R&x�j"G!X�I
51Testing软件测试网5d I.v�a$?�R�r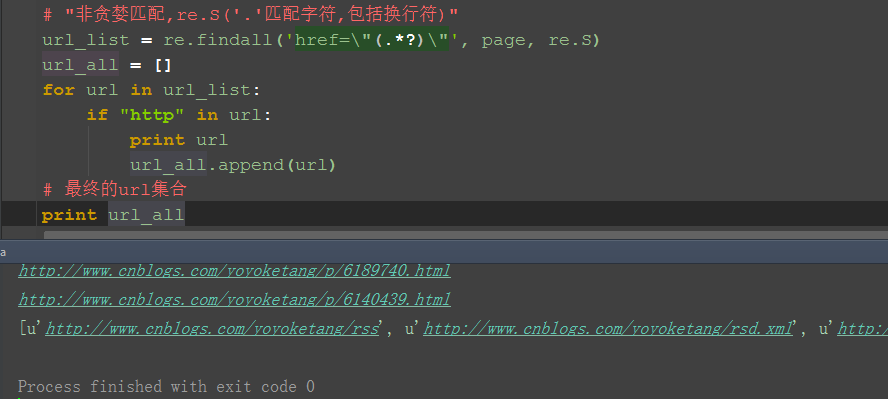
2R�J�U�@�J7N b�E051Testing软件测试网4{-x#`+\3W�i�E/\四、参考代码51Testing软件测试网�j�|.u�{6B6G�N
#coding:utf-8fromseleniumimportwebdriverimportre
driver=webdriver.Firefox()
driver.get("http://www.cnblogs.com/yoyoketang/")
page=driver.page_source#print page#"非贪婪匹配,re.S('.'匹配字符,包括换行符)"url_list = re.findall('href=\"(.*?)\"', page, re.S)
url_all=[]forurlinurl_list:
if"http"inurl:
printurl
url_all.append(url)#最终的url集合printurl_all
收藏
举报
TAG:

